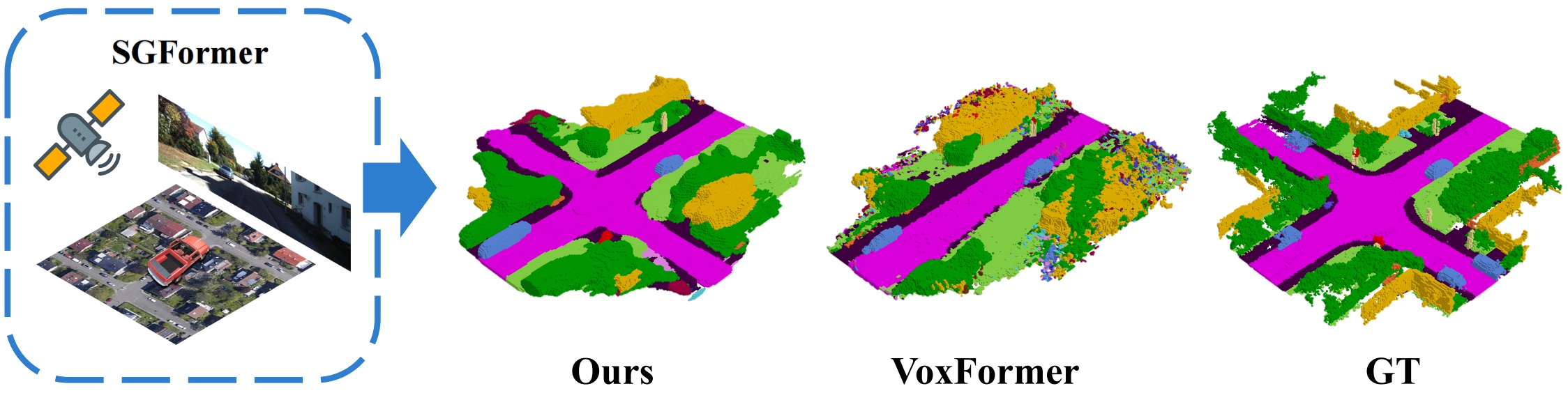
Recently, camera-based solutions have been extensively explored for scene semantic completion (SSC). Despite their success in visible areas, existing methods struggle to capture complete scene semantics due to frequent visual occlusions. To address this limitation, this paper presents the first satellite-ground cooperative SSC framework, i.e., SGFormer, exploring the potential of satellite-ground image pairs in the SSC task. Specifically, we propose a dual-branch architecture that encodes orthogonal satellite and ground views in parallel, unifying them into a common domain. Additionally, we design a ground-view guidance strategy that corrects satellite image biases during feature encoding, addressing misalignment between satellite and ground views. Moreover, we develop an adaptive weighting strategy that balances contributions from satellite and ground views. Experiments demonstrate that SGFormer outperforms the state of the art on SemanticKITTI and SSCBench-KITTI-360 datasets.
Framework Overview
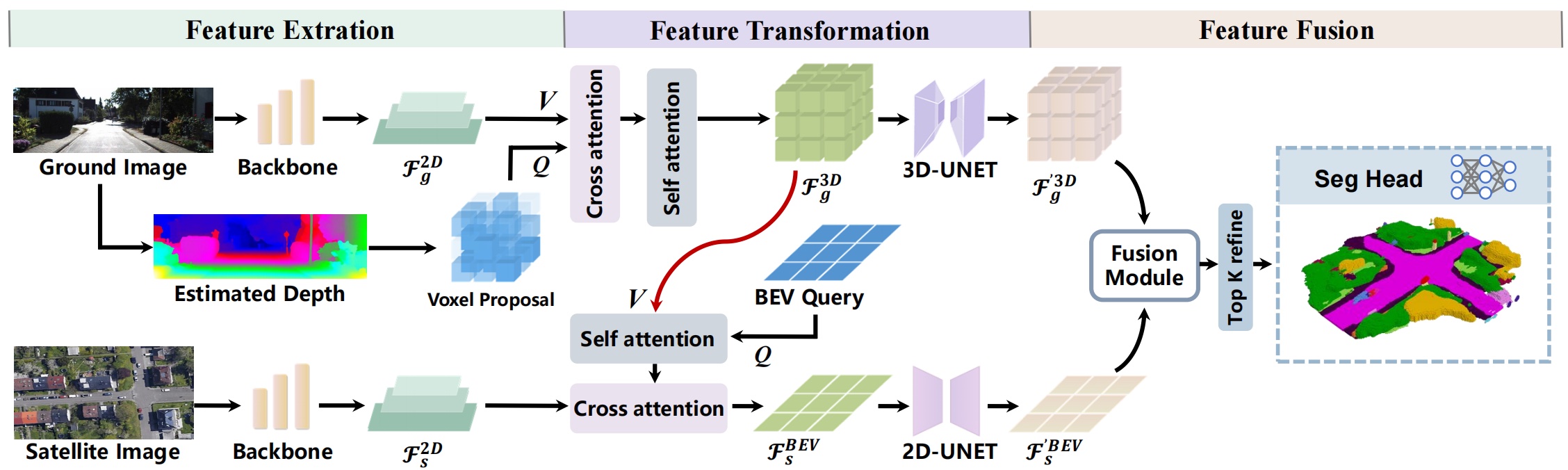
Overall, SGFormer feeds a satellite-ground image pair into similar backbone networks in different branches to extract multi-level feature maps respectively (Left Part). Then, leveraging deformable attention, it transforms satellite and ground features into volume and BEV spaces (Middle Part) for following feature fusion and decoding (Right Part). Specifically, in the ground branch, we use a depth estimator to produce voxel proposals for targeted querying on non-empty feature volumes. In the satellite branch, we fuse vertically squeezed ground-view features into BEV queries to warm up satellite features (Red Line). Before final fusion, encoded features from both branches are enhanced through 2D/3D convolution networks. Our proposed fusion module, which is detailed in the above figure, is able to adaptively fuse satellite and ground features, followed by a seg head to output semantic reconstruction results.
Scene Semantic Completion → Qualitative Performance
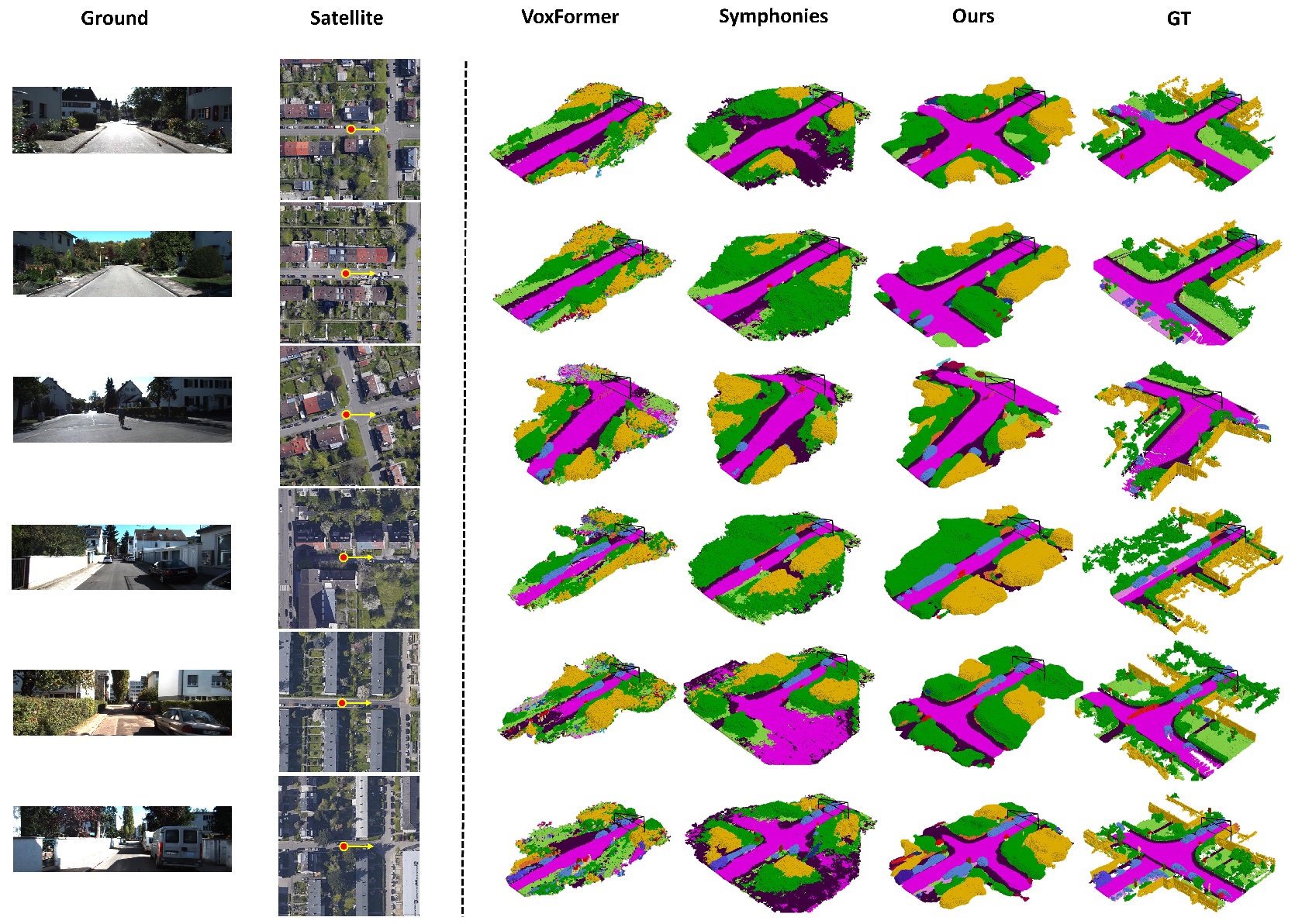
Annotations: (Left): we show satellite-ground image pairs and indicate the vehicle's travel direction as a yellow arrow. (Right): we qualitatively compare scene semantic completion results from SGFormer and other baselines, where SGFormer can produce more complete and accurate semantic reconstruction relying on the satellite-ground fusion.
Annotations: Qualitative results on the validation set of SemanticKITTI.
Annotations: Qualitative results on the test set of SSCBench-KITTI-360.
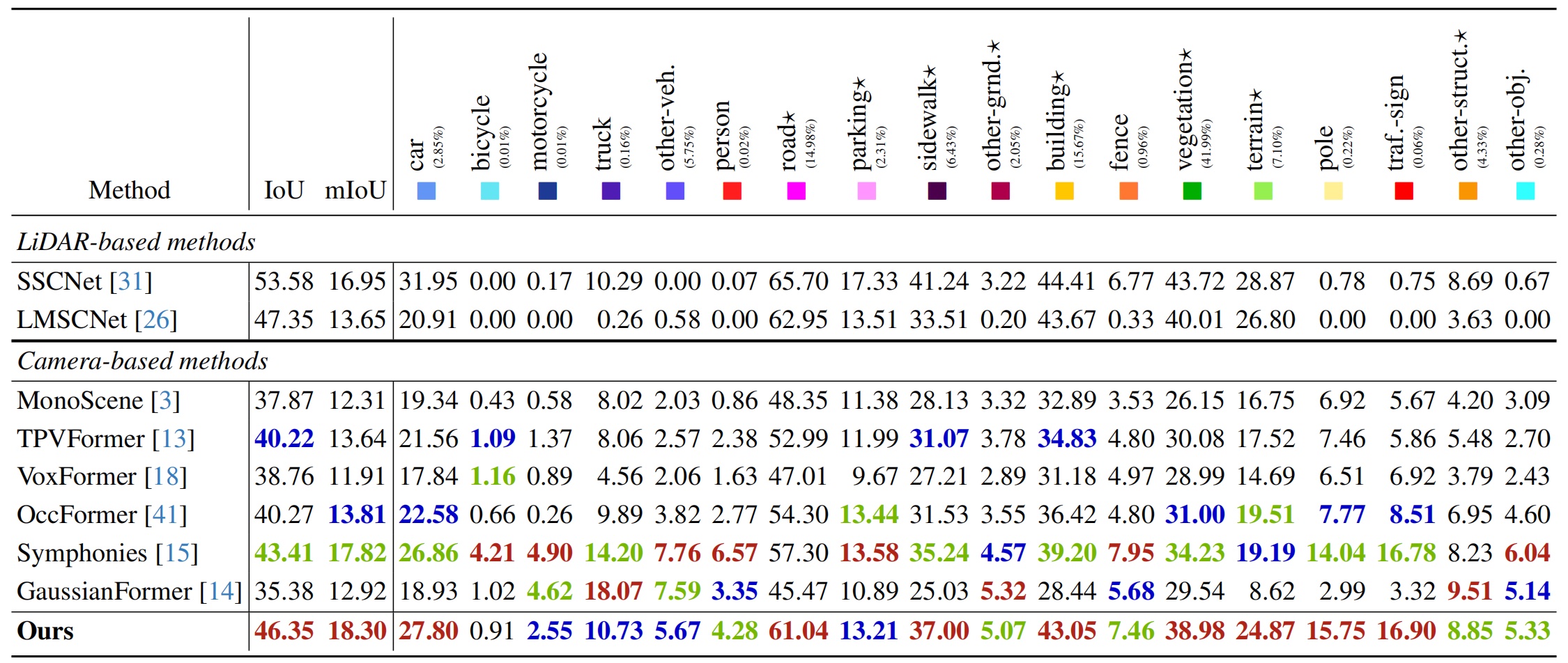
Scene Semantic Completion → Quantitative Performance
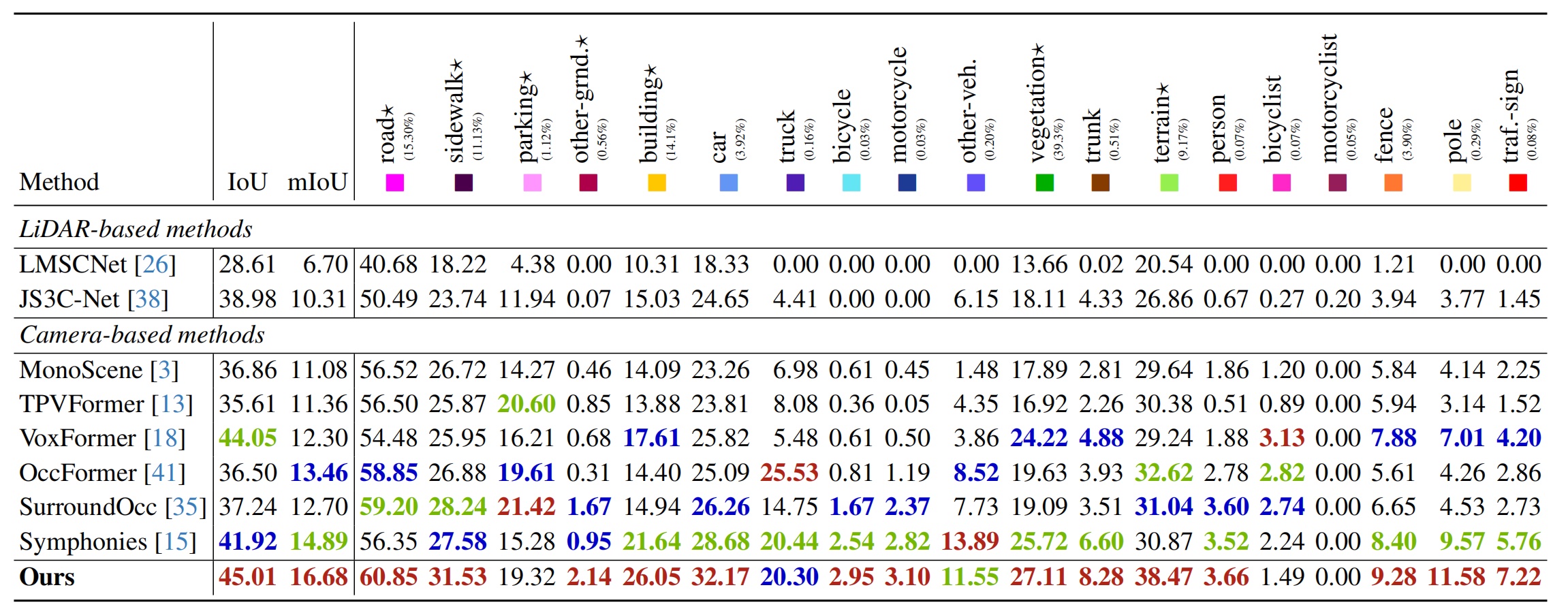
Annotations: Quantitative results on the validation set of SemanticKITTI. ★ denotes the scene layout structures.
Annotations: Quantitative results on the test set of SSCBench-KITTI-360. ★ denotes the scene layout structures.
@article{guo2025sgformersatellitegroundfusion3d,
title={SGFormer: Satellite-Ground Fusion for 3D Semantic Scene Completion},
author={Xiyue Guo and Jiarui Hu and Junjie Hu and Hujun Bao and Guofeng Zhang},
journal={arXiv preprint arXiv:2503.16825},
year={2025}
}