Abstract
TL;DR: We propose an keypoint-free one-shot object pose estimation method that handles low-textured objects without knowing CAD models.
We propose a new method for object pose estimation without CAD models. The previous feature-matching-based method OnePose has shown promising results under a one-shot setting which eliminates the need for CAD models or object-specific training. However, OnePose relies on detecting repeatable image keypoints and is thus prone to failure on low-textured objects. We propose a keypoint-free pose estimation pipeline to remove the need for repeatable keypoint detection. Built upon the detector-free feature matching method LoFTR, we devise a new keypoint-free SfM method to reconstruct a semi-dense point-cloud model for the object. Given a query image for object pose estimation, a 2D-3D matching network directly establishes 2D-3D correspondences between the query image and the reconstructed point-cloud model without first detecting keypoints in the image. Experiments show that the proposed pipeline outperforms existing one-shot CAD-model-free methods by a large margin and is comparable to CAD-model-based methods on LINEMOD even for low-textured objects. We also collect a new dataset composed of 80 sequences of 40 low-textured objects to facilitate future research on one-shot object pose estimation.
Overview video
Pipeline overview
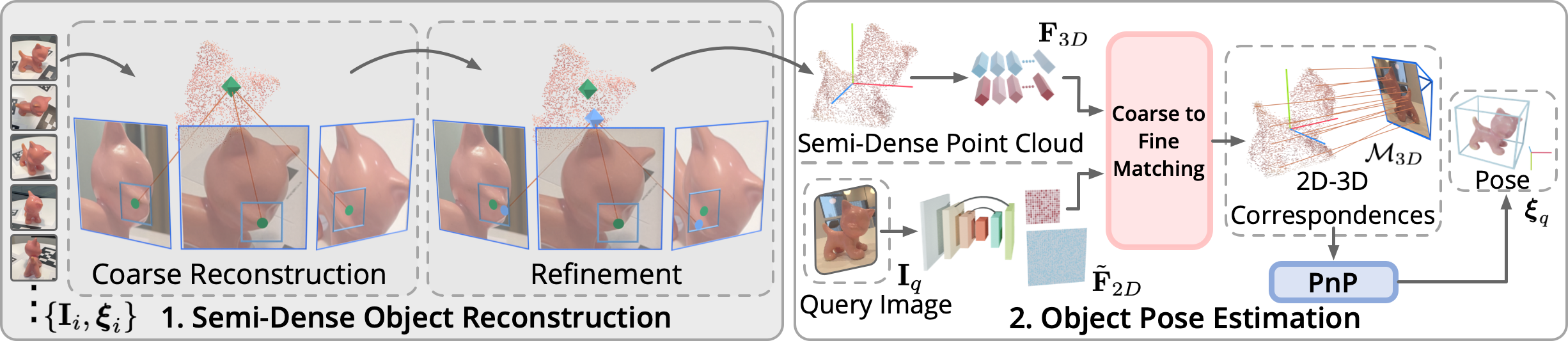
OnePose++ has two main components: $\textbf{1.}$ For each object, given a reference image sequence $\{\mathbf{I}_i\}$ with known object poses $\{\boldsymbol{\xi}_i\}$, our keypoint-free SfM framework reconstructs the semi-dense object point cloud in a coarse-to-fine manner. The coarse reconstruction yields the initial point cloud which is then optimized to obtain an accurate point cloud in the refinement phase. $\textbf{2.}$ At test time, our 2D-3D matching network directly matches a reconstructed object point cloud with a query image $\mathbf{I}_q$ to build 2D-3D correspondences $\mathcal{M}_{3D}$, and then the object pose $\boldsymbol{\xi}_q$ is estimated by solving PnP with $\mathcal{M}_{3D}$.
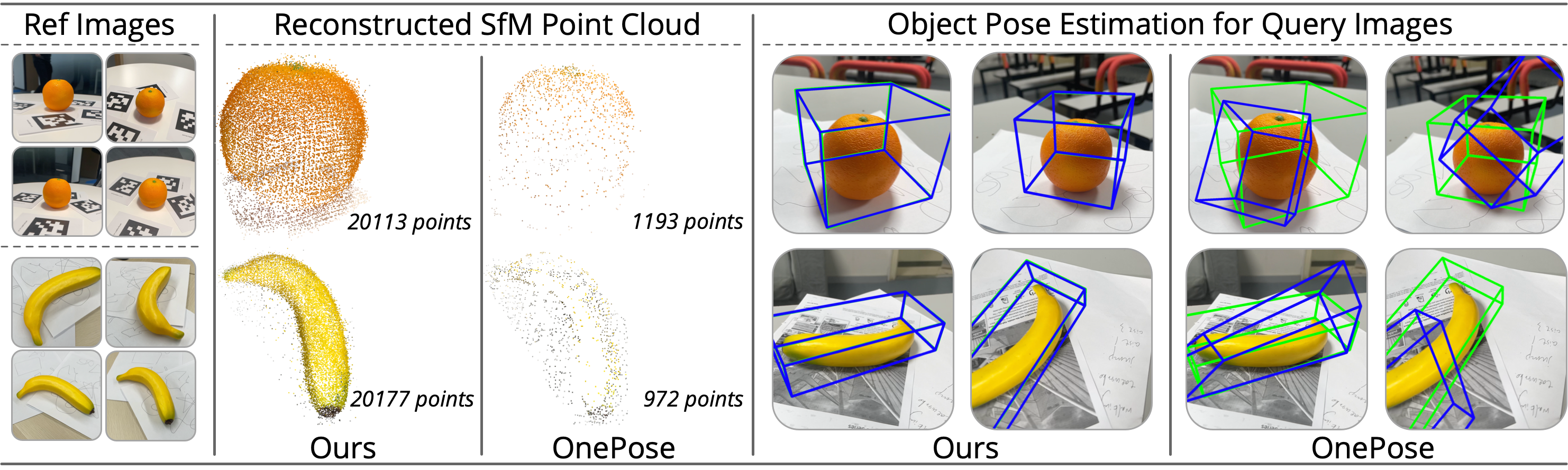
Qualitative comparison with OnePose
Our method achieves more accurate and stable pose estimation for low-textured objects
More qualitative results.
The following figure shows the reconstructed semi-dense object point clouds and the estimated object poses. The ablation part visualizes the 2D and 3D features before and after our 2D-3D attention module. Features become more discriminative as shown by the color contrast.

Citation
@inproceedings{
he2022oneposeplusplus,
title={OnePose++: Keypoint-Free One-Shot Object Pose Estimation without {CAD} Models},
author={Xingyi He and Jiaming Sun and Yuang Wang and Di Huang and Hujun Bao and Xiaowei Zhou},
booktitle={Advances in Neural Information Processing Systems},
year={2022}
}