Pipeline overview
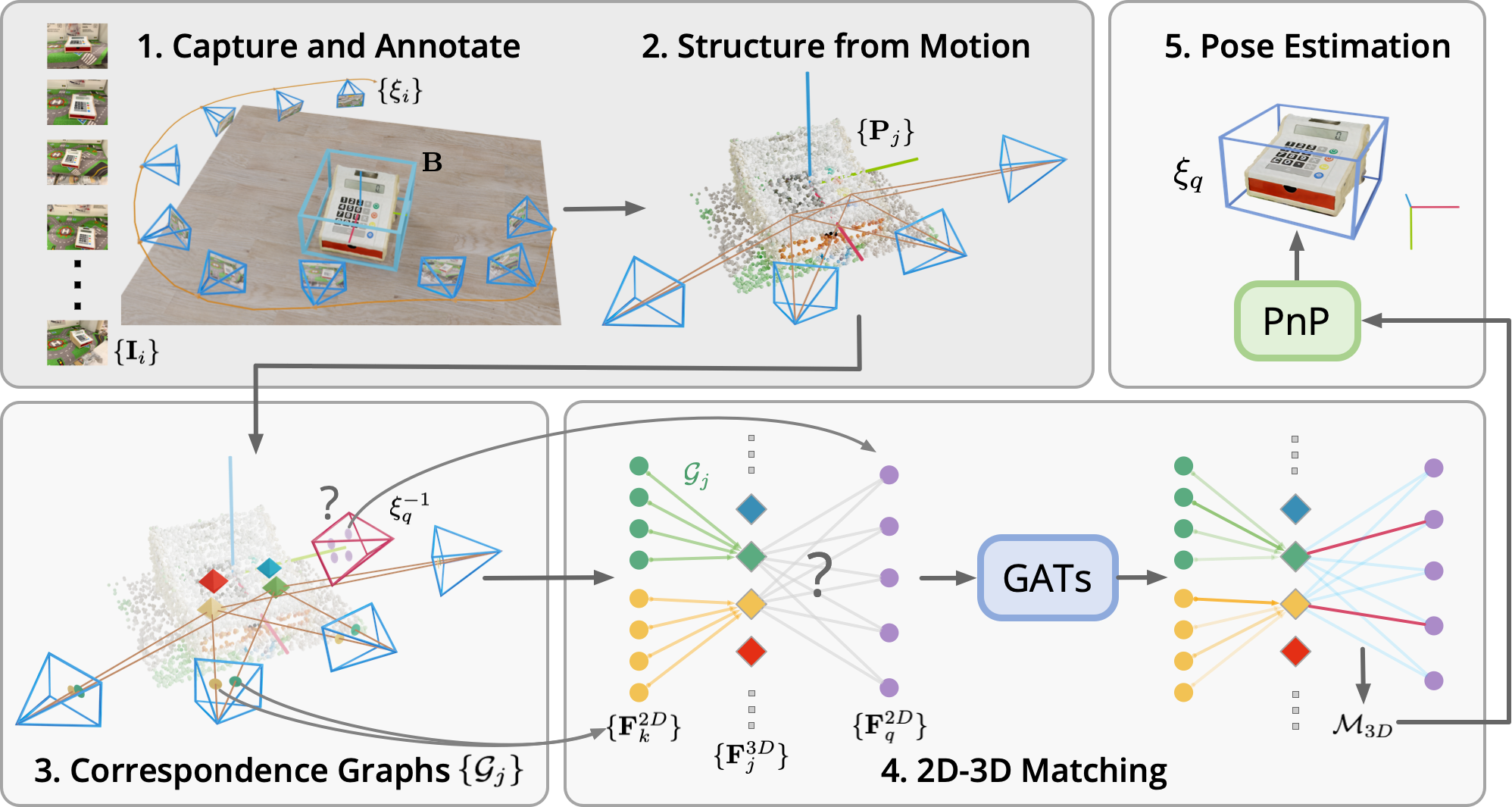
$\textbf{1.}$ For each object, a video scan with RGB frames $\{\mathbf{I}_i\}$ and camera poses $\{\xi_{i}\}$ are collected together with the annotated 3D object bounding box $\mathbf{B}$. $\textbf{2.}$ Structure from Motion (SfM) reconstructs a sparse point cloud $\{\mathbf{P}_j\}$ of the object. $\textbf{3.}$ The correspondence graphs $\{\mathcal{G}_j\}$ are built during SfM, which represent the 2D-3D correspondences in the SfM map. $\textbf{4.}$ 2D descriptors $\{\mathbf{F}_k^{2D}\}$ are aggregated to 3D descriptors $\{\mathbf{F}_j^{3D}\}$ with the aggregration-attention layer. $\{\mathbf{F}_j^{3D}\}$ are later matched with 2D descriptors from the query image $\{\mathbf{F}_q^{2D}\}$ to generate 2D-3D match predictions $\mathcal{M}_{3D}$. $\textbf{5.}$ Finally, the object pose $\xi_{q}$ is computed by solving the PnP problem with $\mathcal{M}_{3D}$.