Abstract
Recently, neural radiance fields (NeRF) have gained significant attention in the field of visual localization. However, existing NeRF-based approaches either lack geometric constraints or require extensive storage for feature matching, limiting their practical applications. To address these challenges, we propose an efficient and novel visual localization approach based on the neural implicit map with complementary features. Specifically, to enforce geometric constraints and reduce storage requirements, we implicitly learn a 3D keypoint descriptor field, avoiding the need to explicitly store point-wise features. To further address the semantic ambiguity of descriptors, we introduce additional semantic contextual feature fields, which enhance the quality and reliability of 2D-3D correspondences. Besides, we propose descriptor similarity distribution alignment to minimize the domain gap between 2D and 3D feature spaces during matching. Finally, we construct the matching graph using both complementary descriptors and contextual features to establish accurate 2D-3D correspondences for 6-DoF pose estimation. Compared with the recent NeRF-based approach, our method achieves a 3$\times$ faster training speed and a 45$\times$ reduction in model storage. Extensive experiments on two widely used datasets demonstrate that our approach outperforms or is highly competitive with other state-of-the-art NeRF-based visual localization methods.
Framework Overview

The whole pipeline of our system. (1) Reconstruction: We employ different parametric encodings ($\mathcal{T}_{geo}$ and $\mathcal{T}_{sem}$) for geometry and semantic branches. Scene properties, including color $c$, SDF $\sigma$, semantic contextual feature $f^{3D}$, and keypoint descriptor $g^{3D}$ are produced by separated shadow decoders ($\mathcal{M}_{geo}$ and $\mathcal{M}_{sem}$). We use pre-trained CNN models (SuperPoint and SAM) to generate 2D feature maps for the optimization of the semantic branch. (2) Localization: We extract 2D descriptors and semantic contextual features for the query image to build the matching graph between 3D points. Then, we estimate the 6-DoF pose based on the 2D-3D correspondence.
Qualitative and Quantitative Results
Visual Localization
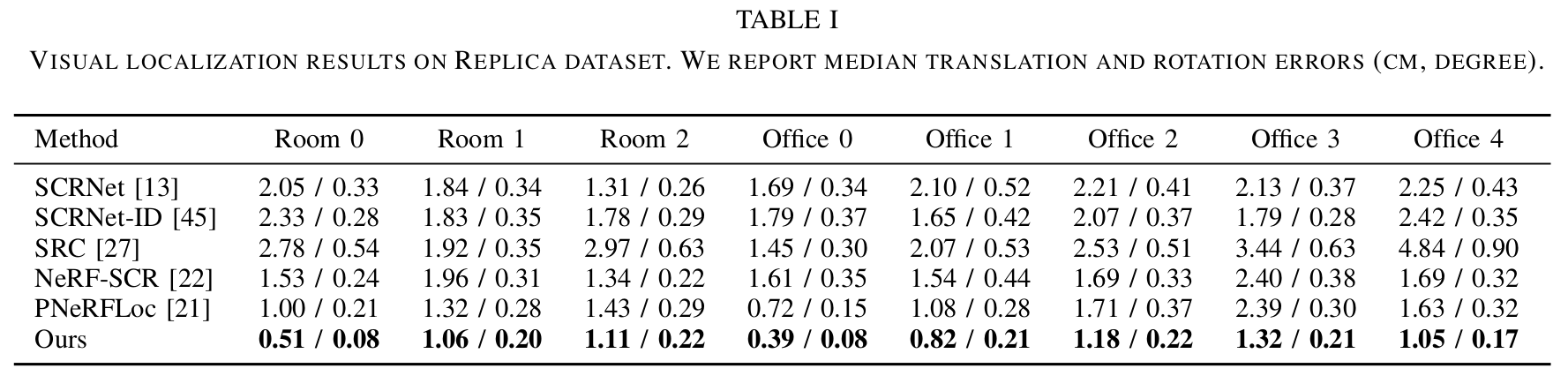
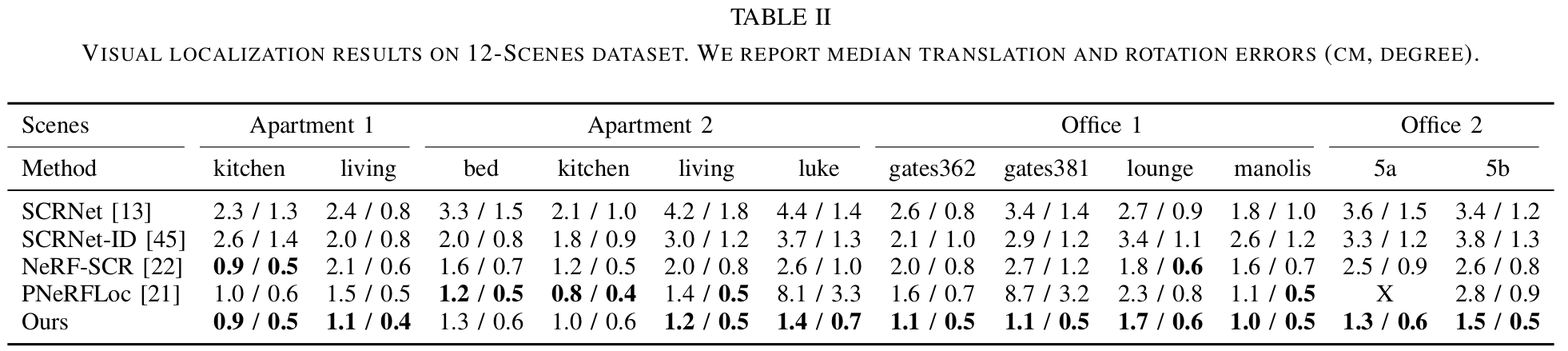
Visual localization results on Replica and 12-Scenes datasets. We report median translation and rotation errors (cm, degree)
Matching and 3D Trajectory

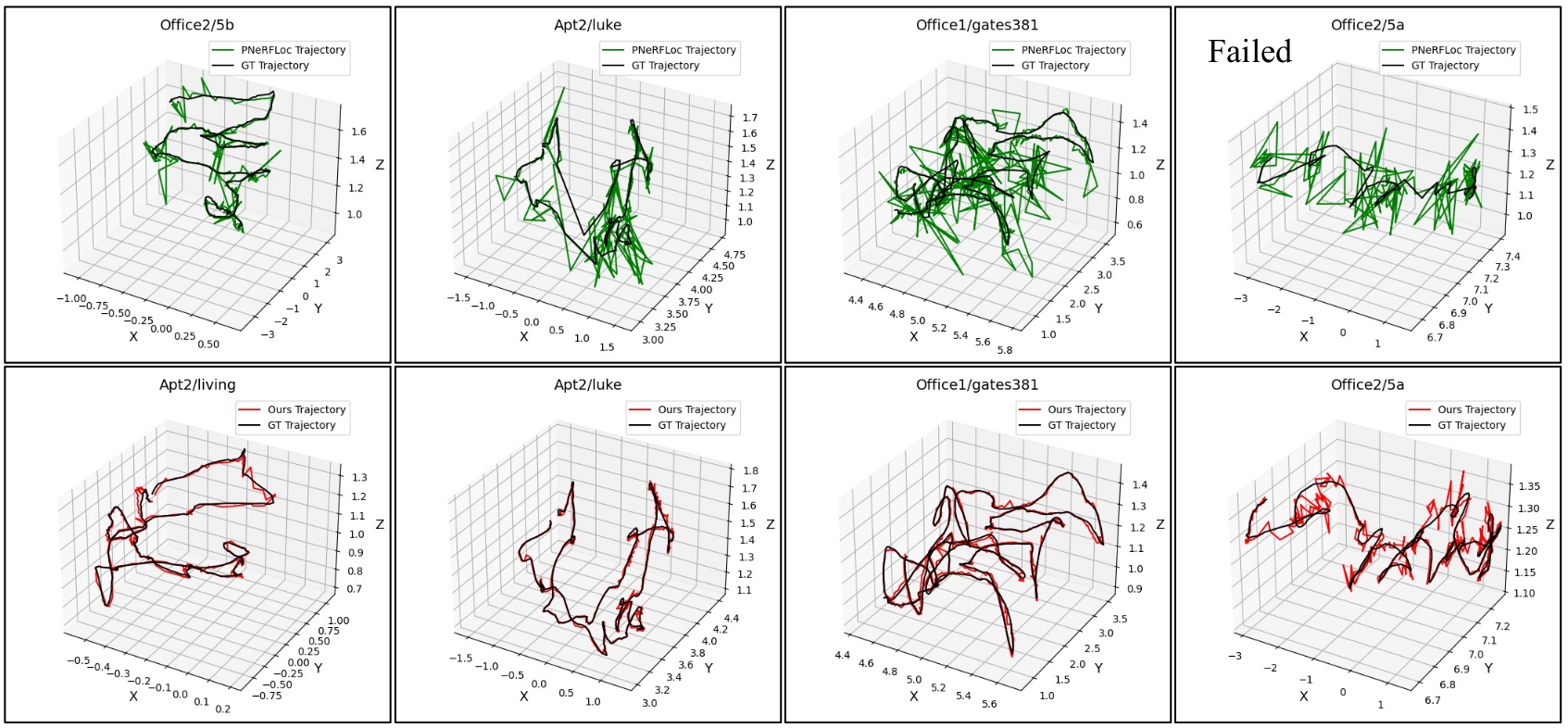
Qualitative results of feature matching and 3D trajectory. We show some matching and 3D results of our method on Replica and 12-Scenes datasets.
BibTeX
@inproceedings{neuraloc,
title={NeuraLoc: Visual Localization in Neural Implicit Map with Dual Complementary Features},
author={Zhai, Hongjia and Zhao, boming and Li, Hai and Pan, Xiaokun and He, Yijia and Cui, Zhaopeng and Bao, Hujun and Zhang, Guofeng},
booktitle={IEEE International Conference on Robotics and Automation},
year={2025}
}