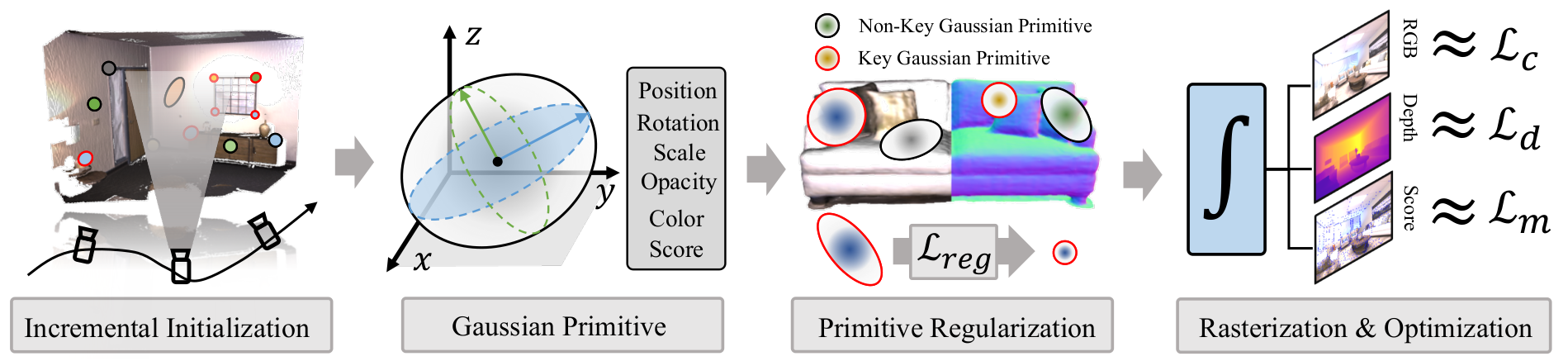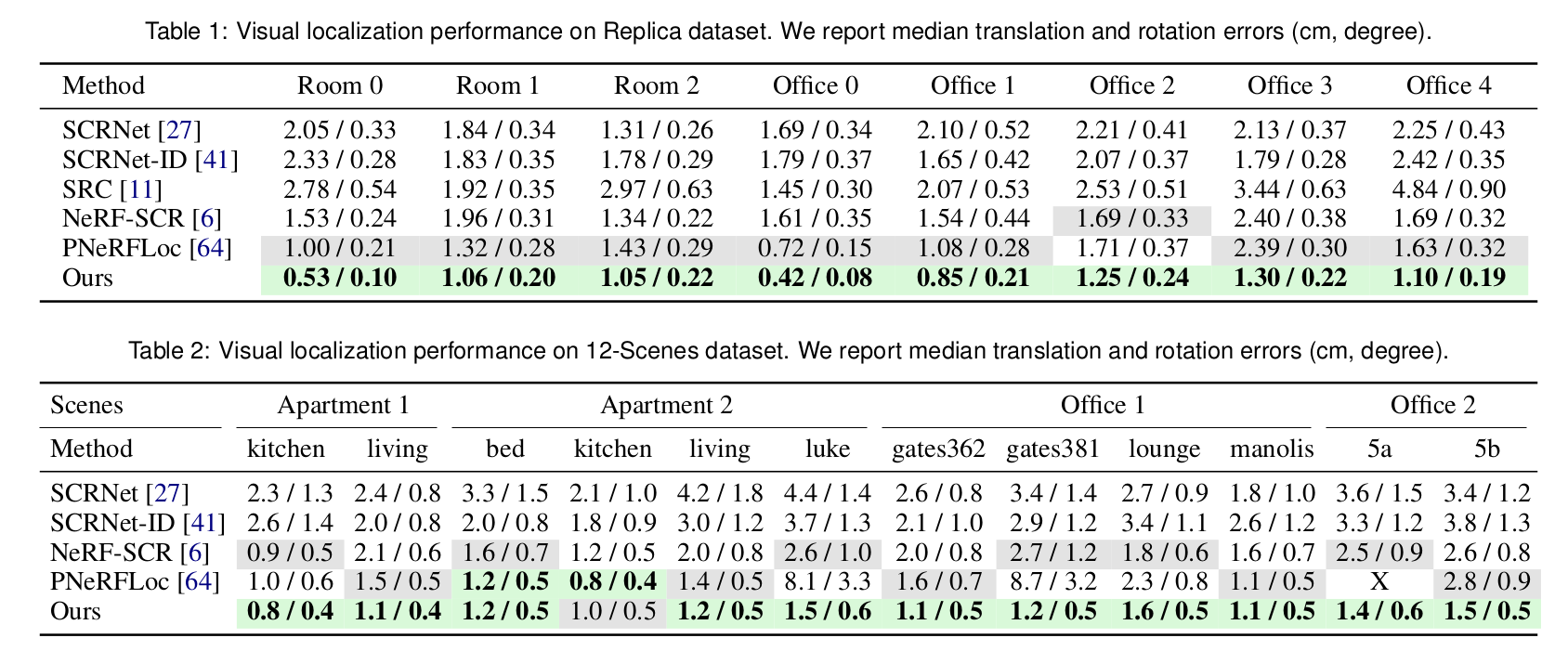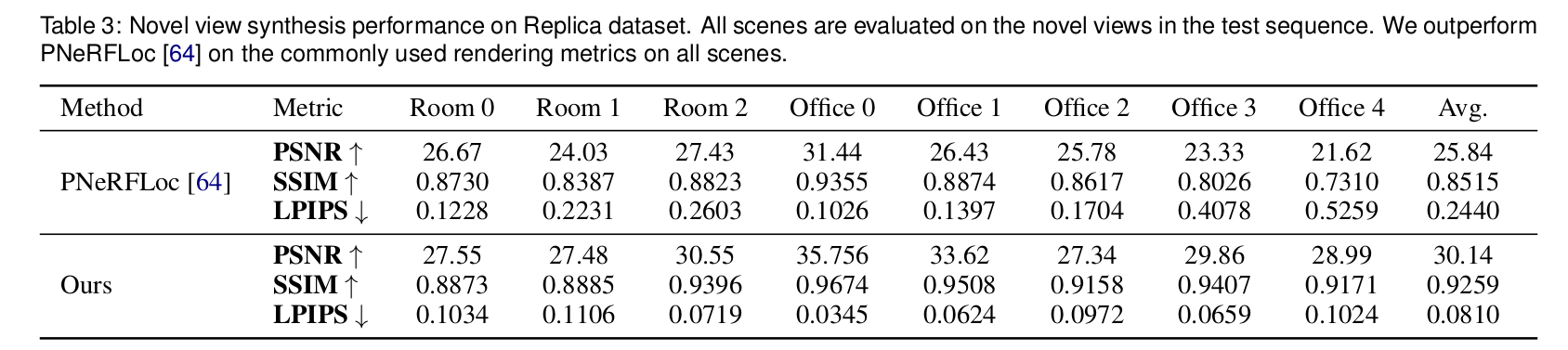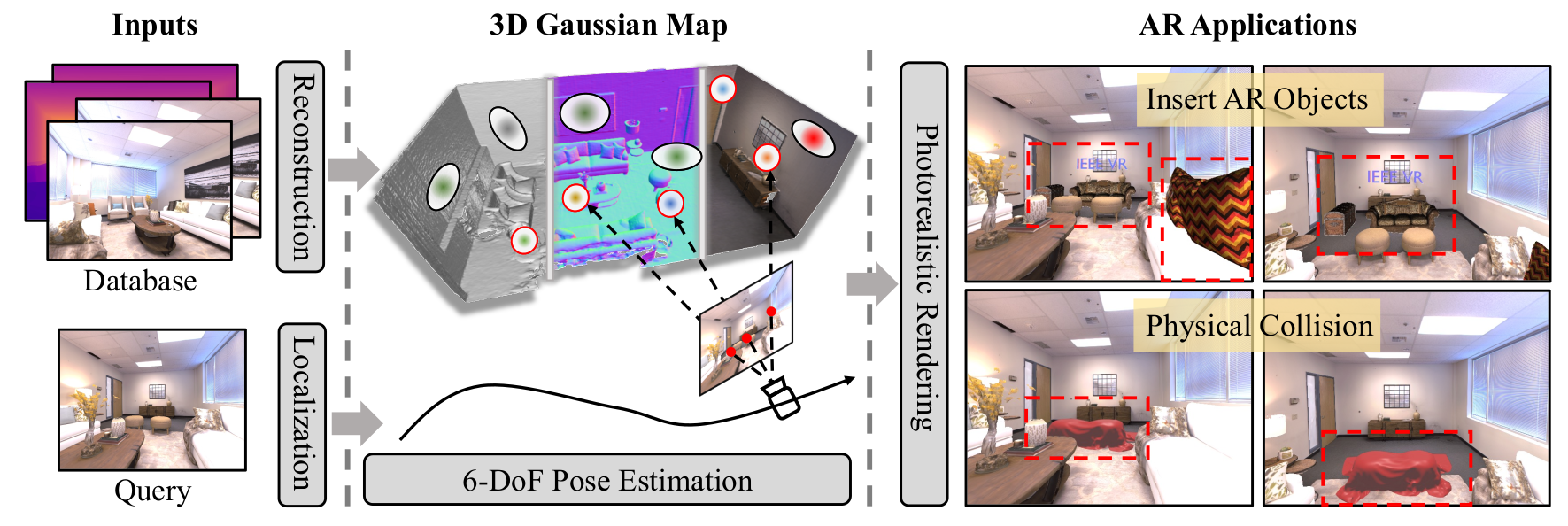
We present SplatLoc, an efficient and novel visual localization approach designed for Augmented Reality (AR). As illustrated in the figure, our system utilizes monocular RGB-D frames to reconstruct the scene using 3D Gaussian primitives. Additionally, with our learned unbiased 3D descriptor fields, we achieve 6-DoF camera pose estimation through precise 2D-3D feature matching. We demonstrate the potential AR applications of our system, such as virtual content insertion and physical collision simulation. We highlight virtual objects with red boxes.