Abstract
Light-weight time-of-flight (ToF) depth sensors are compact and cost-efficient, and thus widely used on mobile devices for tasks such as autofocus and obstacle detection. However, due to the sparse and noisy depth measurements, these sensors have rarely been considered for dense geometry reconstruction. In this work, we present the first dense SLAM system with a monocular camera and a light-weight ToF sensor. Specifically, we propose a multi-modal implicit scene representation that supports rendering both the signals from the RGB camera and light-weight ToF sensor which drives the optimization by comparing with the raw sensor inputs. Moreover, in order to guarantee successful pose tracking and reconstruction, we exploit a predicted depth as an intermediate supervision and develop a coarse-to-fine optimization strategy for efficient learning of the implicit representation. At last, the temporal information is explicitly exploited to deal with the noisy signals from light-weight ToF sensors to improve the accuracy and robustness of the system. Experiments demonstrate that our system well exploits the signals of light-weight ToF sensors and achieves competitive results both on camera tracking and dense scene reconstruction.
Video
YouTube Source
What is the light-weight ToF sensor?
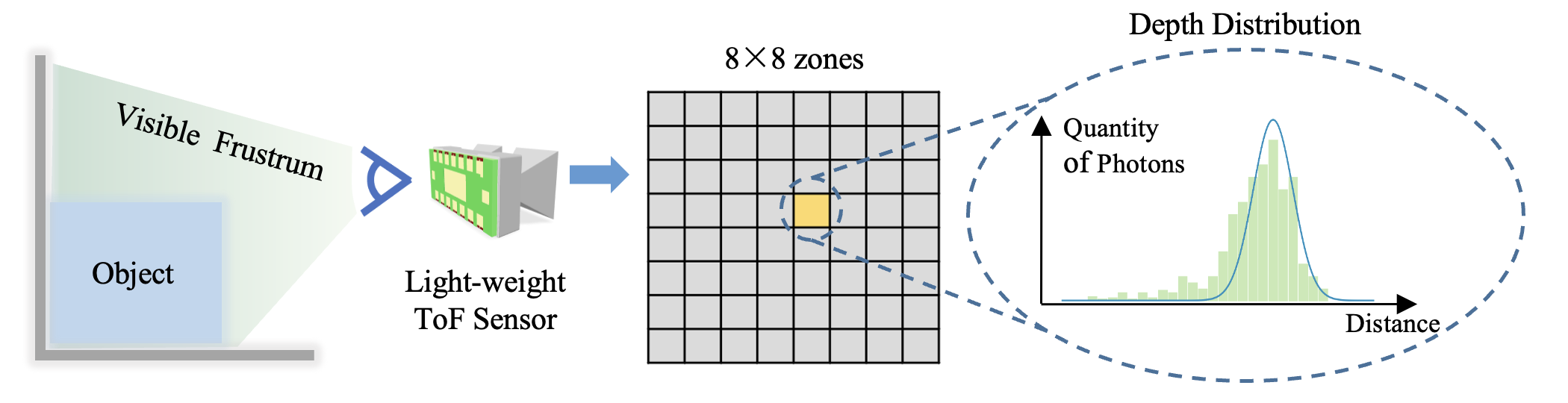
Light-weight ToF sensors are designed to be low-cost, small, and low-energy, which have been massively deployed on mobile devices for the purposes like autofocus, obstacle detection, etc. Due to the light-weight electronic design, the depth measured by these sensors has more uncertainty (i.e., in a distribution instead of single depth value) and low spatial resolution (e.g., ≤ 10×10). Let's use the VL53L5CX as an example to explain the sensing principle of the light-weight ToF sensor. For conventional ToF sensors, the output is typically in a resolution higher than 10 thousand pixels and measures the per-pixel distance along the ray from the optical center to the observed surfaces. In contrast, VL53L5CX (denoted as L5) provides depth distributions with an extremely low resolution of 8 × 8 zones, covering 63° diagonal FoV in total.
Framework Overview
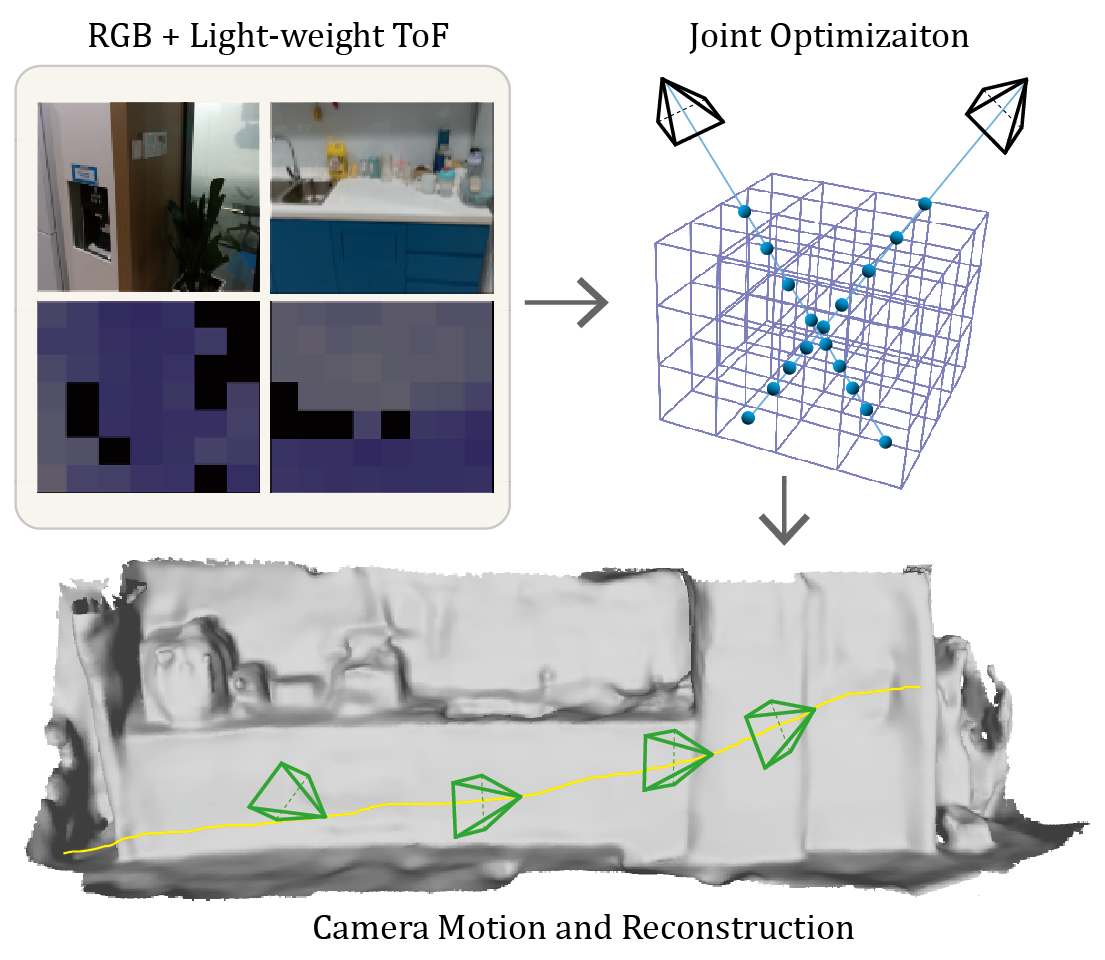
Our method uses a monocular camera and a light-weight ToF sensor as input and recovers both camera motion and the scene structures. Through differentiable rendering, our method can render multi-modal signals, including color images, depth images and zone-level L5 signals. Both the scene structure and the camera poses are optimized by minimizing the re-rendering loss.
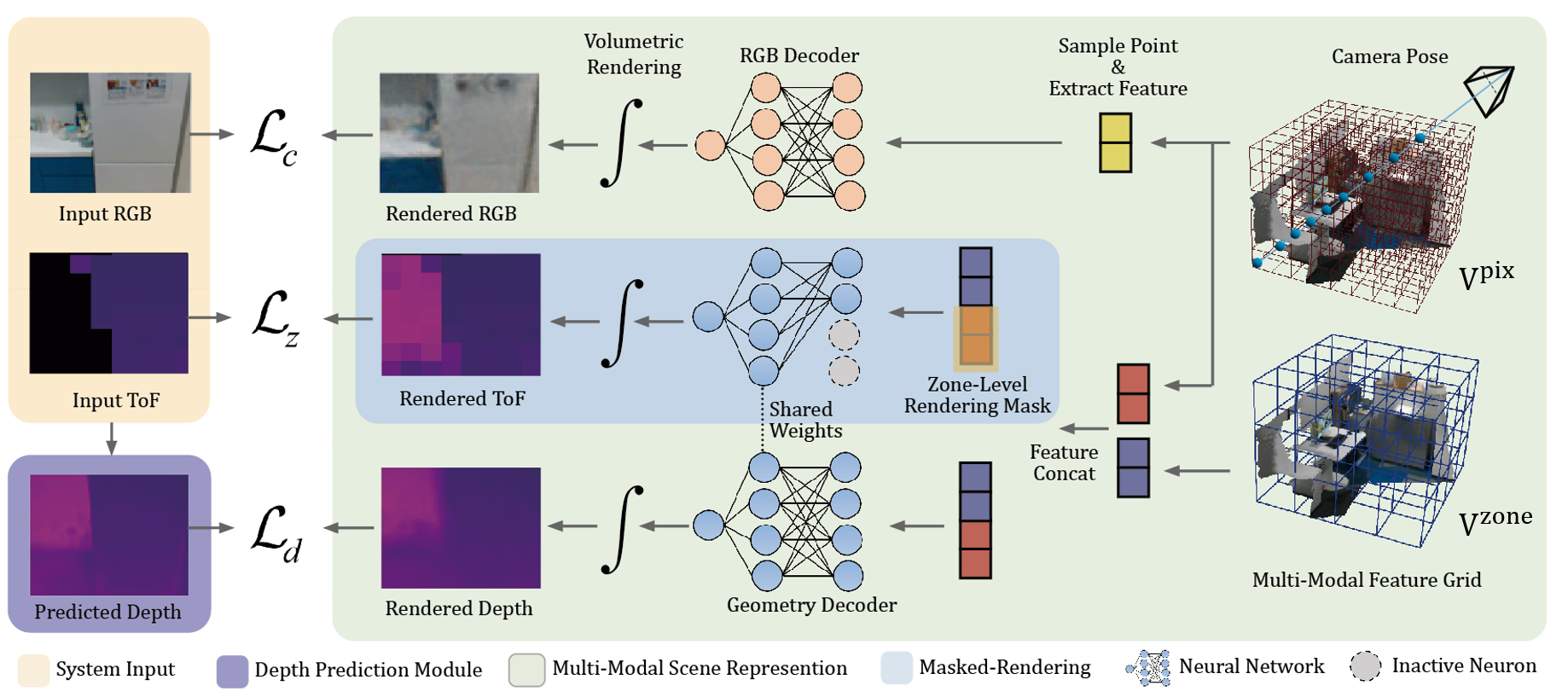
Based on the characteristics of L5's signals, we design the first dense SLAM system with a monocular camera and a light-weight ToF sensor. Specifically, we first propose a multi-modal implicit scene representation which enables rendering L5 signals together with the common RGB image and depth maps. To guarantee successful tracking and mapping, we exploit a depth prediction model DELTAR to predict intermediate per-pixel depth maps as additional supervision. By minimizing the difference between the rendered signals and input/predicted ones, we can simultaneously optimize the camera pose and scene structure in a coarse-to-fine way. Furthermore, since the depth prediction may contain severe artifacts when there is a large portion of missing L5 signals, we propose to refine the L5 signals with temporal filtering techniques to enhance the depth prediction module.
Qualitative Reconstruction Results

We compare our method with two categories of baselines: (a) learning-based SLAM methods including iMAP and NICE-SLAM; (b) traditional SLAM methods including KinectFusion, ElasticFusion and BundleFusion. Since all other methods only support RGB-D input, we use the RGB image and the predicted depth map by DELTAR as the system input. Note that none of these methods can work well with only raw L5 zone-level depths or take it as additional inputs. Our method is able to produce high-quality 3D models with smooth surfaces and high accuracy. It is easy to notice that our reconstruction result has much fewer artifacts and noisy points. Since NICE-SLAM relies on high-quality depth input, its performance is poor given the noisy and unreliable depth input.
BibTeX
@inproceedings{tofslam,
title={Multi-Modal Neural Radiance Field for Monocular Dense SLAM with a Light-Weight ToF Sensor},
author={Liu Xinyang and Li Yijin and Teng Yanbin and Bao Hujun and Zhang Guofeng and Zhang Yinda and Cui Zhaopeng},
booktitle={International Conference on Computer Vision (ICCV)},
year={2023}
}