PVO: Panoptic Visual Odometry
CVPR 2023
Weicai Ye*1,2, Xinyue Lan*1,2, Shuo Chen1,2, Yuhang Ming3,4, Xinyuan Yu1,2, Hujun Bao1,2, Zhaopeng Cui1, Guofeng Zhang1,2†
1State Key Lab of CAD & CG, Zhejiang University
2ZJU-SenseTime Joint Lab of 3D Vision
3School of Computer Science, Hangzhou Dianzi University
4Visual Information Laboratory, University of Bristol
* denotes equal contribution
† denotes the corresponding author
Abstract
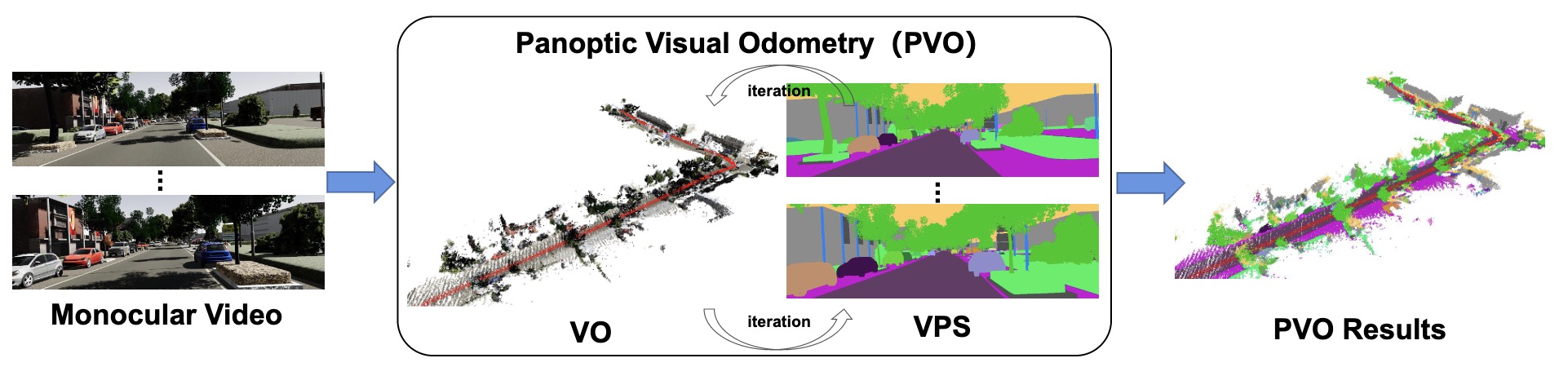
We present PVO, a novel panoptic visual odometry framework to achieve more comprehensive modeling of the scene motion, geometry, and panoptic segmentation information. Our PVO models visual odometry (VO) and video panoptic segmentation (VPS) in a unified view, which makes the two tasks mutually beneficial. Specifically, we introduce a panoptic update module into the VO Module with the guidance of image panoptic segmentation. This Panoptic-Enhanced VO Module can alleviate the impact of dynamic objects in the camera pose estimation with a panoptic-aware dynamic mask. On the other hand, the VO-Enhanced VPS Module also improves the segmentation accuracy by fusing the panoptic segmentation result of the current frame on the fly to the adjacent frames, using geometric information such as camera pose, depth, and optical flow obtained from the VO Module. These two modules contribute to each other through recurrent iterative optimization. Extensive experiments demonstrate that PVO outperforms state-of-the-art methods in both visual odometry and video panoptic segmentation tasks.
Overview Video
System overview
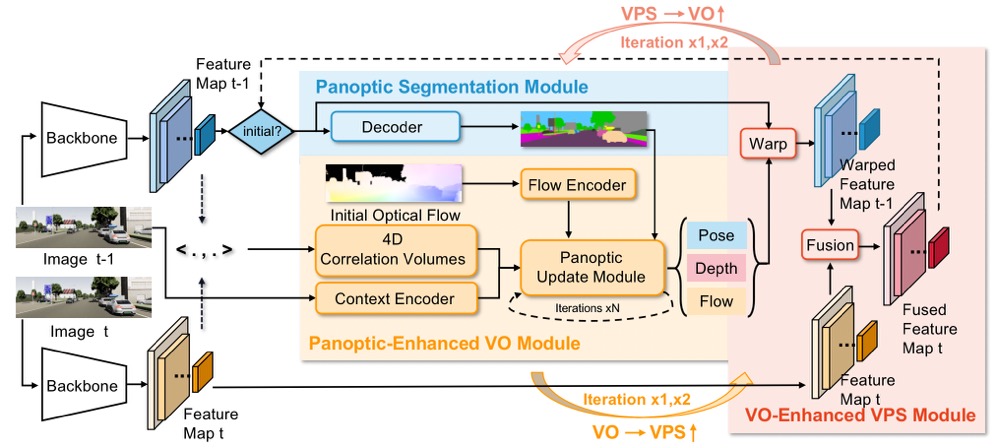
Panoptic Visual Odometry Architecture. Our method consists of three modules, namely, an image panoptic segmentation module for system initialization (blue), a Panoptic-Enhanced VO Module (orange), and a VO-Enhanced VPS Module (red). The last two modules contribute to each other in a recurrent iterative manner.
Experiments
We compare our method with several state-of-the-art methods for both two tasks. For visual odometry, we conduct experiments on three datasets with dynamic scenes: VKITTI2, KITTI, and TUM RGBD dynamic sequences, to evaluate the accuracy of the camera trajectory, primarily using Absolute Trajectory Error. For video panoptic segmentation, we evaluate the VPQ metric used in FuseTrack on VKITTI2, Cityscapes and VIPER datasets.
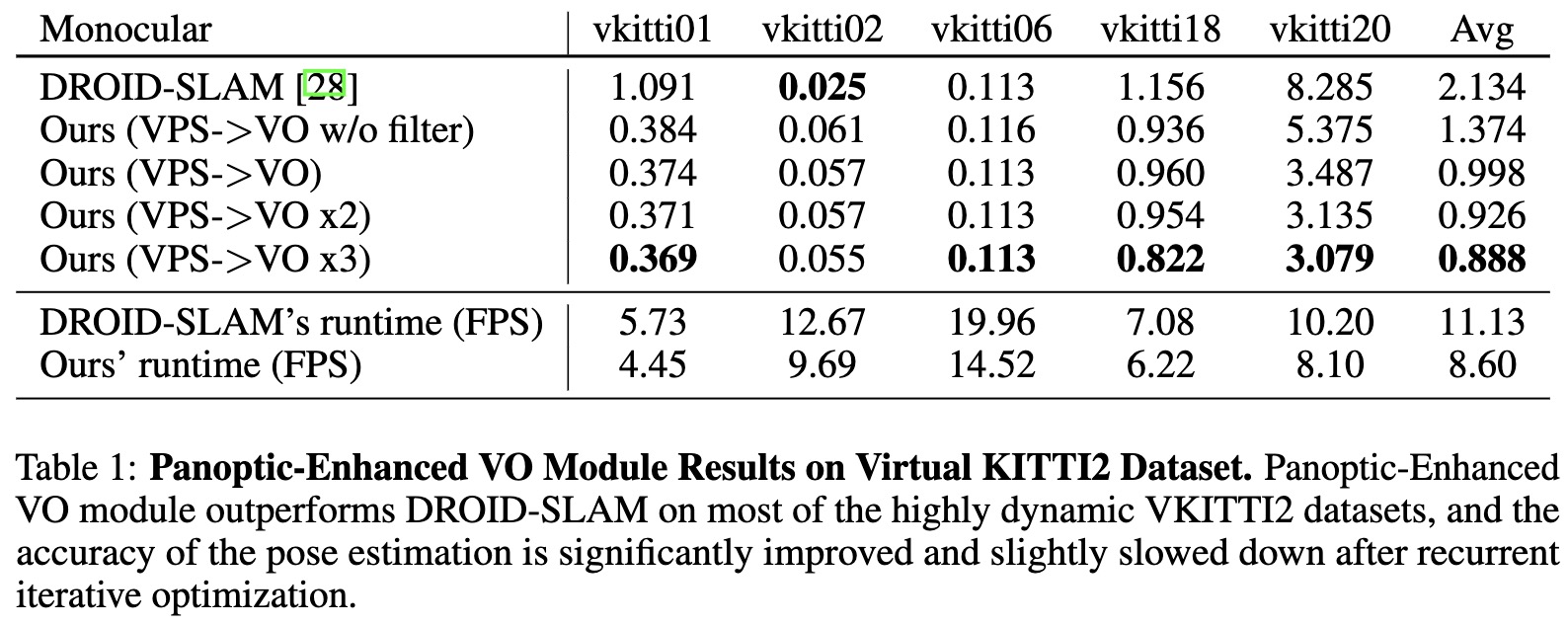
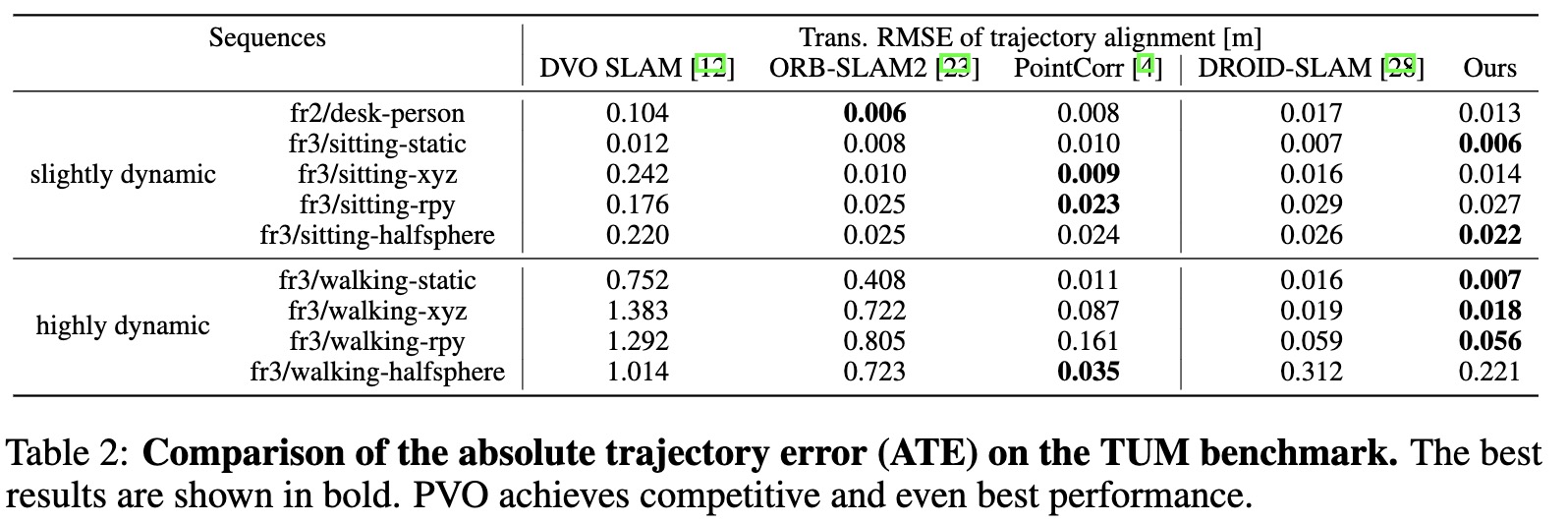
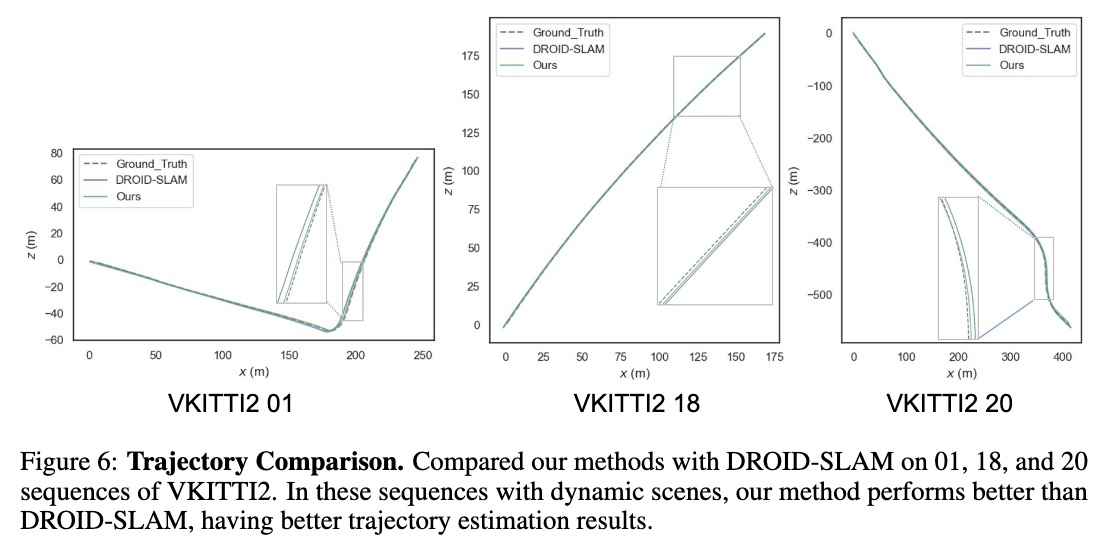

As shown in Tab. 1 and Fig. 6, our PVO outperforms DROID-SLAM by a large margin except for the vkitti02 sequence. Compared with DROID-SLAM, we achieve nearly half of the pose estimation error in DROID-SLAM, shown in Fig. 7, which demonstrates good generalization ability of PVO. Tab. 2 demonstrates that our methods perform better on all datasets, compared with DROID-SLAM. We achieve the best results on 5 dataset out of 9 datasets. Note that PointCorr is a state-of-the-art RGB-D SLAM using Point Correlation, while ours only used monocular RGB video.
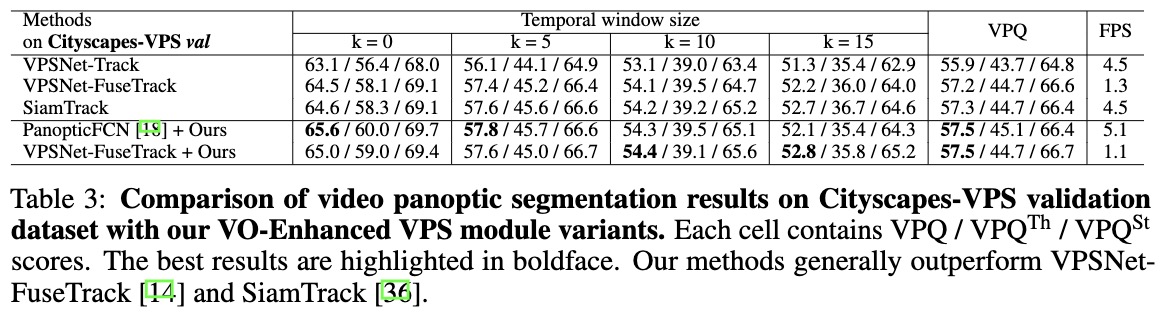
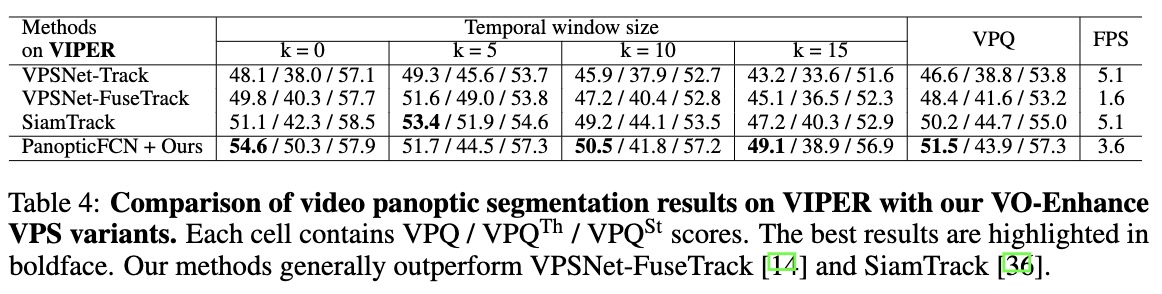
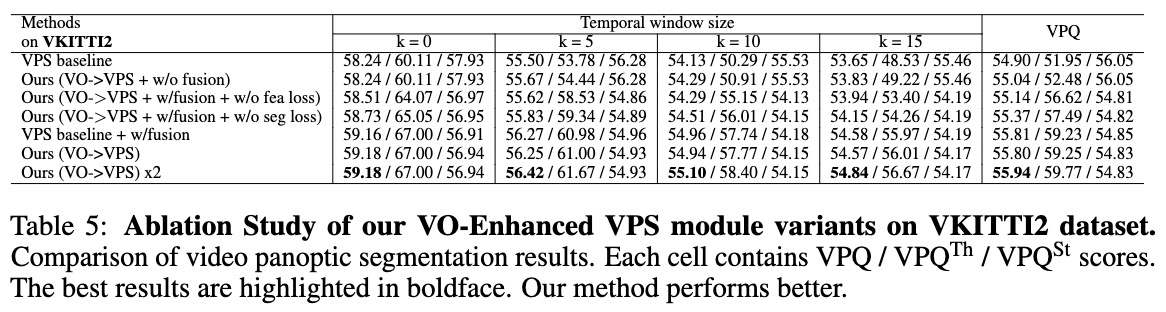
We observe that our method with PanopticFCN outperforms the state-of-the-art method, achieving +1.6% VPQ higher than VPSNet-Track on Cityscapes-Val dataset. Compared with VPSNet-FuseTrack, our method with PanopticFCN achieves much higher scores (51.5VPQ vs. 48.4 VPQ) on VIPER dataset. As shown in Tab. 5, the VO-Enhanced VPS module is effective in improving segmentation accuracy and tracking consistency.
PVO Demo
Panoptic Visual Odometry takes a monocular video as input and outputs the panoptic 3D map while simultaneously localizing the camera itself with respect to the map. We show the panoptic 3D map produced by our method. The red triangle indicates the camera pose, and different colors indicate different instances. We also apply PVO to perform video editing: arbitrarily manipulating the motion patterns of objects in original videos.
Citation
@InProceedings{Ye2023PVO,
author = {Ye, Weicai and Lan, Xinyue and Chen, Shuo and Ming, Yuhang and Yu, Xingyuan and Bao, Hujun and Cui, Zhaopeng and Zhang, Guofeng},
title = {{PVO: Panoptic Visual Odometry}},
booktitle = {{Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}},
month = {June},
year = {2023},
pages = {9579-9589}
}
Acknowledgements
This work was partially supported by NSF of China (No. 61932003) and ZJU-SenseTime Joint Lab of 3D Vision. Weicai Ye was partially supported by China Scholarship Council (No. 202206320316).