Existing inverse rendering combined with neural rendering methods can only perform editable novel view synthesis on object-specific scenes, while we present intrinsic neural radiance fields, dubbed IntrinsicNeRF, which introduce intrinsic decomposition into the NeRF-based neural rendering method and can extend its application to room-scale scenes. Since intrinsic decomposition is a fundamentally under-constrained inverse problem, we propose a novel distance-aware point sampling and adaptive reflectance iterative clustering optimization method, which enables IntrinsicNeRF with traditional intrinsic decomposition constraints to be trained in an unsupervised manner, resulting in multi-view consistent intrinsic decomposition results. To cope with the problem that different adjacent instances of similar reflectance in a scene are incorrectly clustered together, we further propose a hierarchical clustering method with coarse-to-fine optimization to obtain a fast hierarchical indexing representation. It supports compelling real-time augmented applications such as recoloring and illumination variation. Extensive experiments and editing samples on both object-specific/room-scale scenes and synthetic/real-word data demonstrate that we can obtain consistent intrinsic decomposition results and high-fidelity novel view synthesis even for challenging sequences.
Method
Given multi-view posed images of static scenes, IntrinsicNeRF can factorize them into the multi-view consistent components: reflectance, shading, and residual layers. The decomposition can support online applications such as scene recoloring, illumination variation, and editable novel view synthesis.
Framework
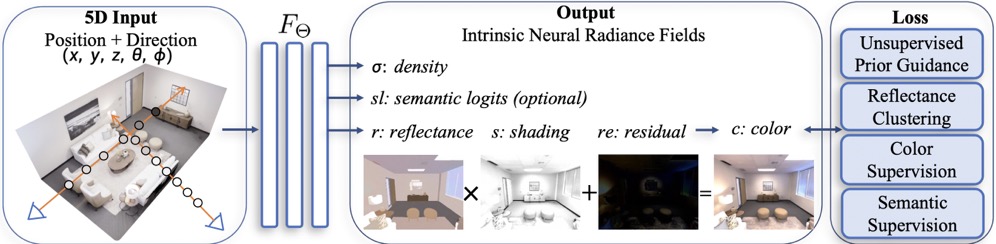
IntrinsicNeRF takes the sampled spatial coordinate point and direction as input, and outputs the density, reflectance, shading, and residual term. The semantic branch is optional. Unsupervised Prior and Reflectance Clustering are exploited to train the IntrinsicNeRF in an unsupervised manner.
With the semantic branch, we can obtain the hierarchical clustering and indexing representation which supports real-time editing.
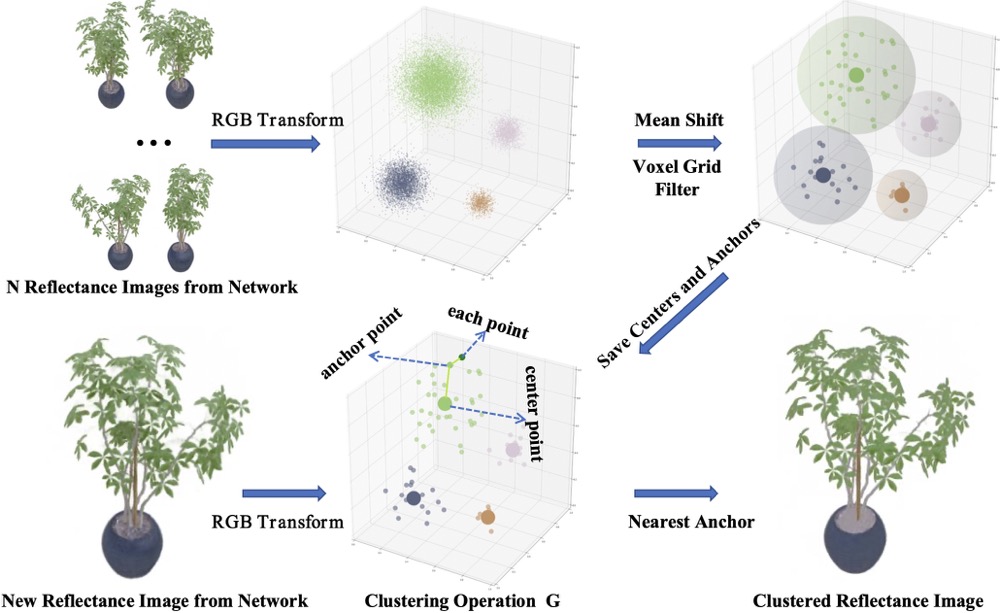
Adaptive Reflectance Iterative Clustering
The color of the reflectance pixels is first converted to better cluster reflectances and then clustered with mean shift algorithm.
The voxel grid filter is performed to accelerate the processing of the cluster operation G,
which considers the category of the nearest anchor points as the category of each point
and saves the category of the center point as the target clustered category.
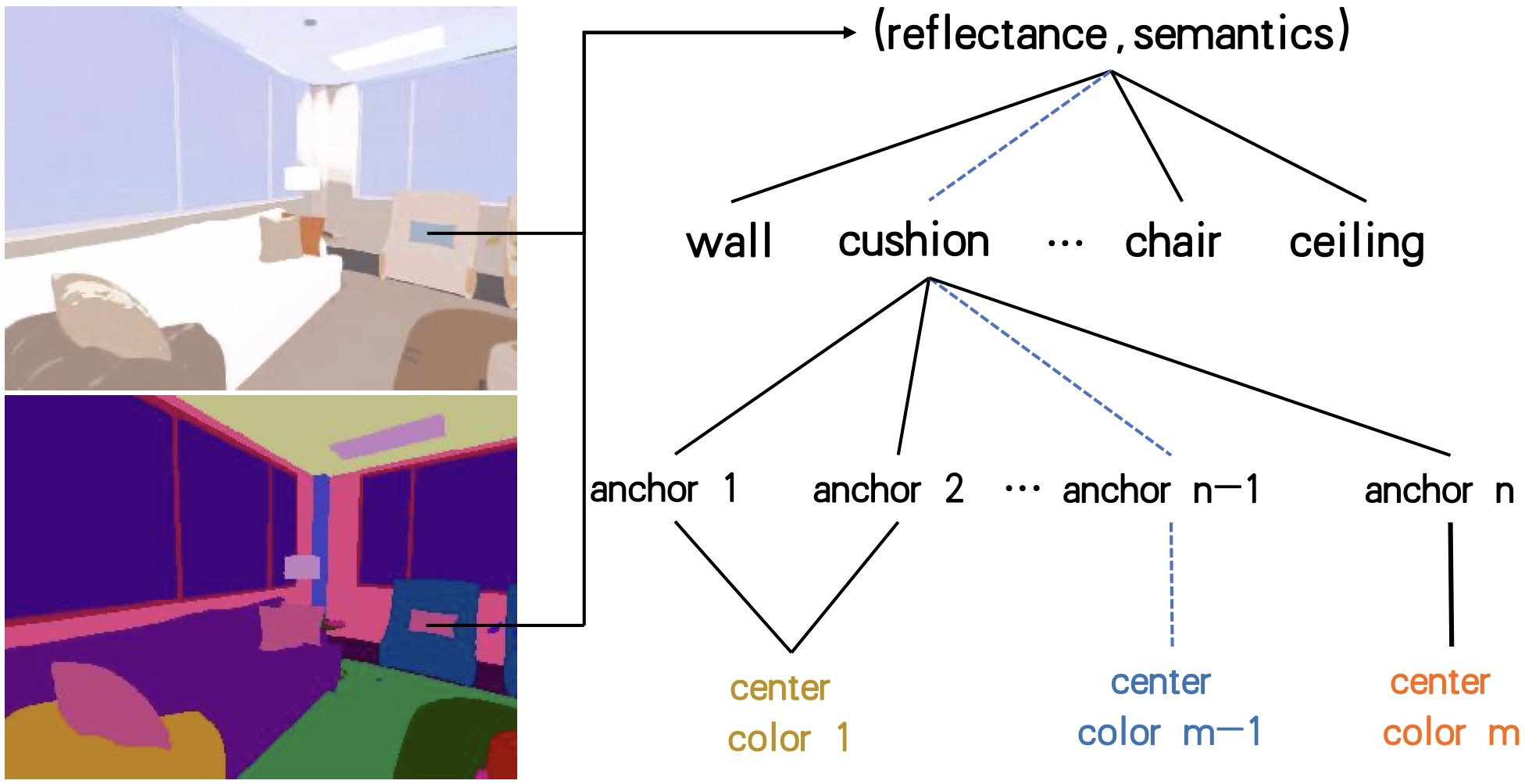
Hierarchical Reflectance Clustering and Indexing
Given the reflectance value of each pixel and the corresponding semantic label,
hierarchical clustering operation first query the semantics of each pixel,
and output the results of the clustering operation. The clustering information of each pixel is stored in a tree structure,
which yields a hierarchical indexing representation.
Applicability: Scene Recoloring
The reflectance predicted by the IntrinsicNeRF network is saved as [Semantic category, reflectance category],
and the last iteration of hierarchical iterative clustering method will save the reflectance categories in all semantic categories of the whole scene.
Therefore, the [Semantic category, reflectance category] label can be used to quickly find the reflectance value of each pixel point.
Based on this representation, we can perform scene recoloring in real-time, just by simply modifying the color of a certain reflectance category,
the reflectance values of all pixels in the video belonging to that category can be modified at the same time, and then the edited video can be reconstructed using the modified reflectance with the original shading and residual through Equation 2.
The edited scene can perform novel view synthesis with the Play button ($\triangleright$).
Applicability: Illumination Variation
Since our IntrinsicNeRF can decompose residual terms besides Lambertian assumptions,
which may be properties such as specular illumination, we can adjust its overall brightness directly
through the sliding buttons of the video editing software. We can enhance the light or diminish it,
to see the effect of different light intensities.
Applicability: Editable Novel View Synthesis
Our IntrinsicNeRF gives the NeRF the ability to model additional fundamental properties of the scene,
and the original novel view synthesis functionality is retained.
The effects of our video editing application above such as scene recoloring can be applied to the editable novel view synthesis,
maintaining consistency.
Video Editing Software
We have also developed a convenient video augmented editing software, to facilitate the user to perform object or scene editing.
Overview Video
Citation
@inproceedings{Ye2023IntrinsicNeRF,
title={{IntrinsicNeRF: Learning Intrinsic Neural Radiance Fields for Editable Novel View Synthesis}},
author={Ye, Weicai and Chen, Shuo and Bao, Chong and Bao, Hujun and Pollefeys, Marc and Cui, Zhaopeng and Zhang, Guofeng},
booktitle={{Proceedings of the IEEE/CVF International Conference on Computer Vision}},
year={2023}
}
Acknowledgements
The authors thank Yuanqing Zhang for providing us with the pre-trained model of InvRender, Jiarun Liu for reproducing the results of NeRFactor and PhySG. We thank Hai Li and Jundan Luo for proofreading the paper. This work was partially supported by NSF of China (No. 61932003) and ZJU-SenseTime Joint Lab of 3D Vision. Weicai Ye was partially supported by China Scholarship Council (No. 202206320316).