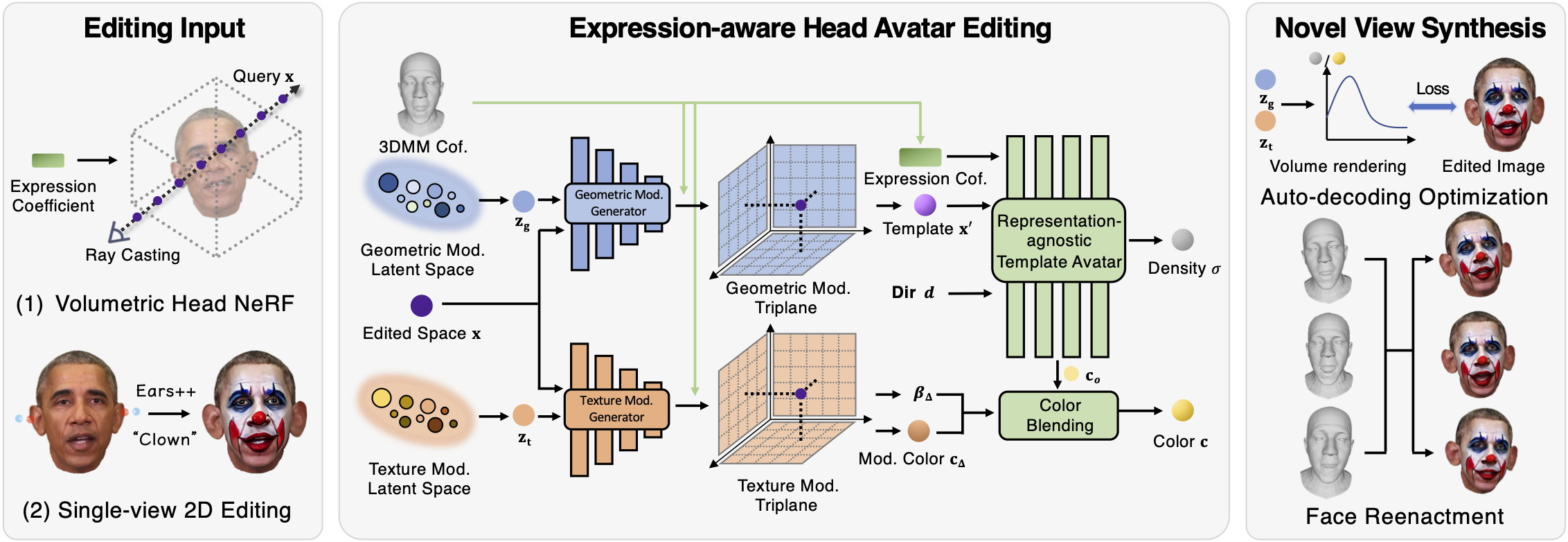
Deploy Geneavatar to your own volumetric avatar representation avatar_model need three steps:
- Load modification generative models:
- Add per-sample deformation and color blendering to the volume rendering pipeline of your own avatar representation
avatar_modellike: - Use a PTI-inversion paradigm
project.pyto edit youravatar_modelwith a single edited image where avatar rendering function should be overwritten by your own avatar method:
def setup_geneavatar(model_path):
geneavatar = GeneAvatar(model_path)
return geneavatar
"""
Avatar volume rendering pipeline
"""
...
# (GeneAvatar addition) deform the sample points in volume rendering
sample_points = sample_points + genavatar.forward_geo(vertices_3DMM, sample_points)
...
# avatar rendering
density, template_color = avatar_model(sample_points)
...
# (GeneAvatar addition) color blendering
color = genavatar.forward_color(vertices_3DMM, sample_points, template_color)
...
"""
Project.py: perform auto-decoding optimization on a single-edited image to lift 2D editing effect to 3D avatar.
"""
def synthesis(data, avatar_model):
"""
Replace your avatar rendering function here.
"""
preds = avatar_model.render(data)
return preds
...