Abstract
TL;DR: We propose a detector-free structure from motion framework that eliminates the requirement of keypoint detection and can recover poses even on challenging texture-poor scenes.
We propose a new structure-from-motion framework to recover accurate camera poses and point clouds from unordered images. Traditional SfM systems typically rely on the successful detection of repeatable keypoints across multiple views as the first step, which is difficult for texture-poor scenes, and poor keypoint detection may break down the whole SfM system. We propose a new detector-free SfM framework to draw benefits from the recent success of detector-free matchers to avoid the early determination of keypoints, while solving the multi-view inconsistency issue of detector-free matchers. Specifically, our framework first reconstructs a coarse SfM model from quantized detector-free matches. Then, it refines the model by a novel iterative refinement pipeline, which iterates between an attention-based multi-view matching module to refine feature tracks and a geometry refinement module to improve the reconstruction accuracy. Experiments demonstrate that the proposed framework outperforms existing detector-based SfM systems on common benchmark datasets. We also collect a texture-poor SfM dataset to demonstrate the capability of our framework to reconstruct texture-poor scenes. Based on this framework, we take the $\textit{first place}$ in Image Matching Challenge 2023.
Motivation
For the texture-poor scene, detector-based SfM fails due to the poor repeatability of detected keypoints at the beginning:
Our detector-free SfM framework leverages detector-free matching and achieves complete reconstruction with highly accurate camera poses:
Pipeline overview
Our framework reconstruct the scene with a coarse-to-fine manner to solve the multi-view inconsistency problem of detector-free matchers. Beginning with a collection of unordered images, the $\textbf{Coarse SfM}$ stage generates an initial SfM model based on multi-view matches from a detector-free matcher. Then, the $\textbf{Iterative Refinement}$ stage improves the accuracy of the SfM model by alternating between the feature track refinement module and the geometry refinement module.
Qualitative comparison on IMC 2021 dataset
On the scenes collected from internet and with large viewpoint and illumination changes, our framework achieves more accurate poses estimation.
Qualitative comparison on the proposed Texture-Poor SfM dataset
Due to the severe low-textured scenario and viewpoint changes in the Texture-Poor SfM dataset, detector-based methods struggle with poor keypoint detection and lead to failed reconstruction. Thanks to the detector-free design, our framework achieves significantly higher accuracy and more complete reconstructions.
Applications
The recovered poses by our framework on challenging scenes such as texture-poor objects can benefit the downstream tasks, including novel view synthesis and dense reconstruction.
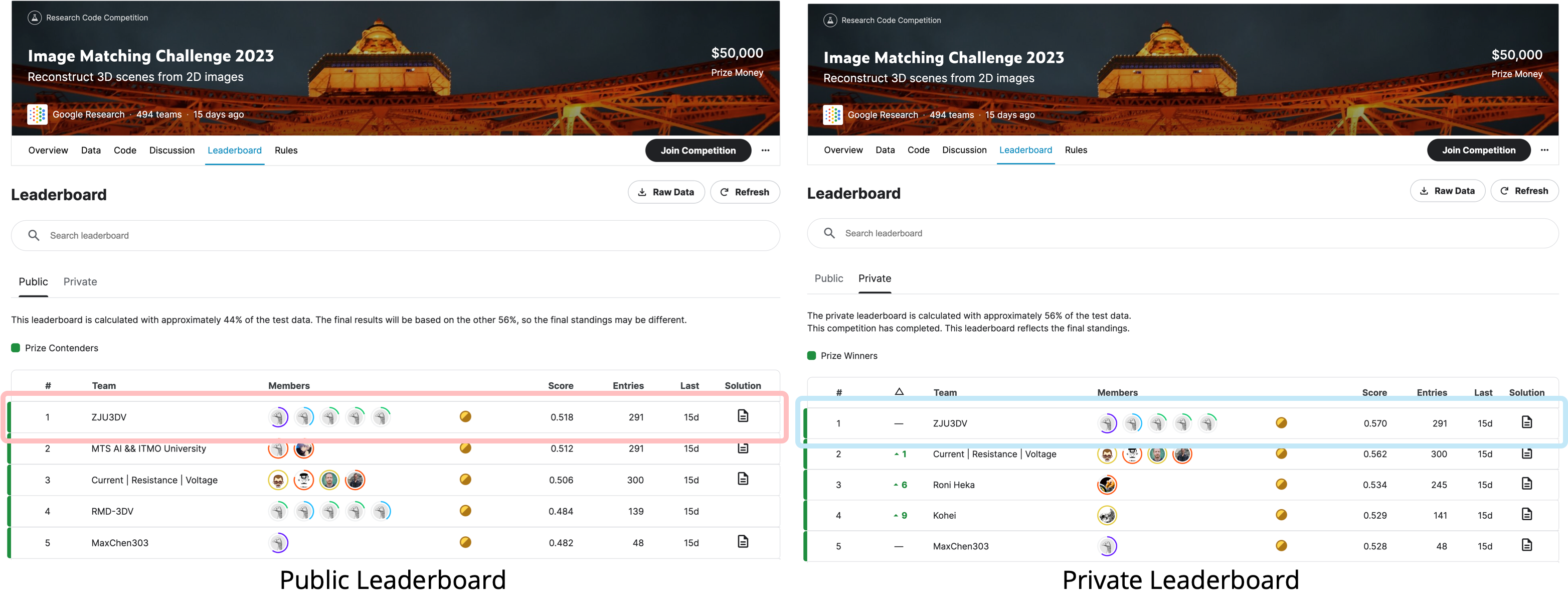
Image Matching Challenge (IMC) 2023
Our framework can be easily integrated with sparse detectors and matchers to perform reconstruction on challenging outdoor scenes. Our solution achieved the $\textit{first place}$ (out of 494 teams) in IMC 2023, where using detector-free matches and refinement phase in pipeline attributed significantly to the final winning. More details of our solution can be found here.
Citation
@article{he2024dfsfm,
title={Detector-Free Structure from Motion},
author={He, Xingyi and Sun, Jiaming and Wang, Yifan and Peng, Sida and Huang, Qixing and Bao, Hujun and Zhou, Xiaowei},
journal={{CVPR}},
year={2024}
}