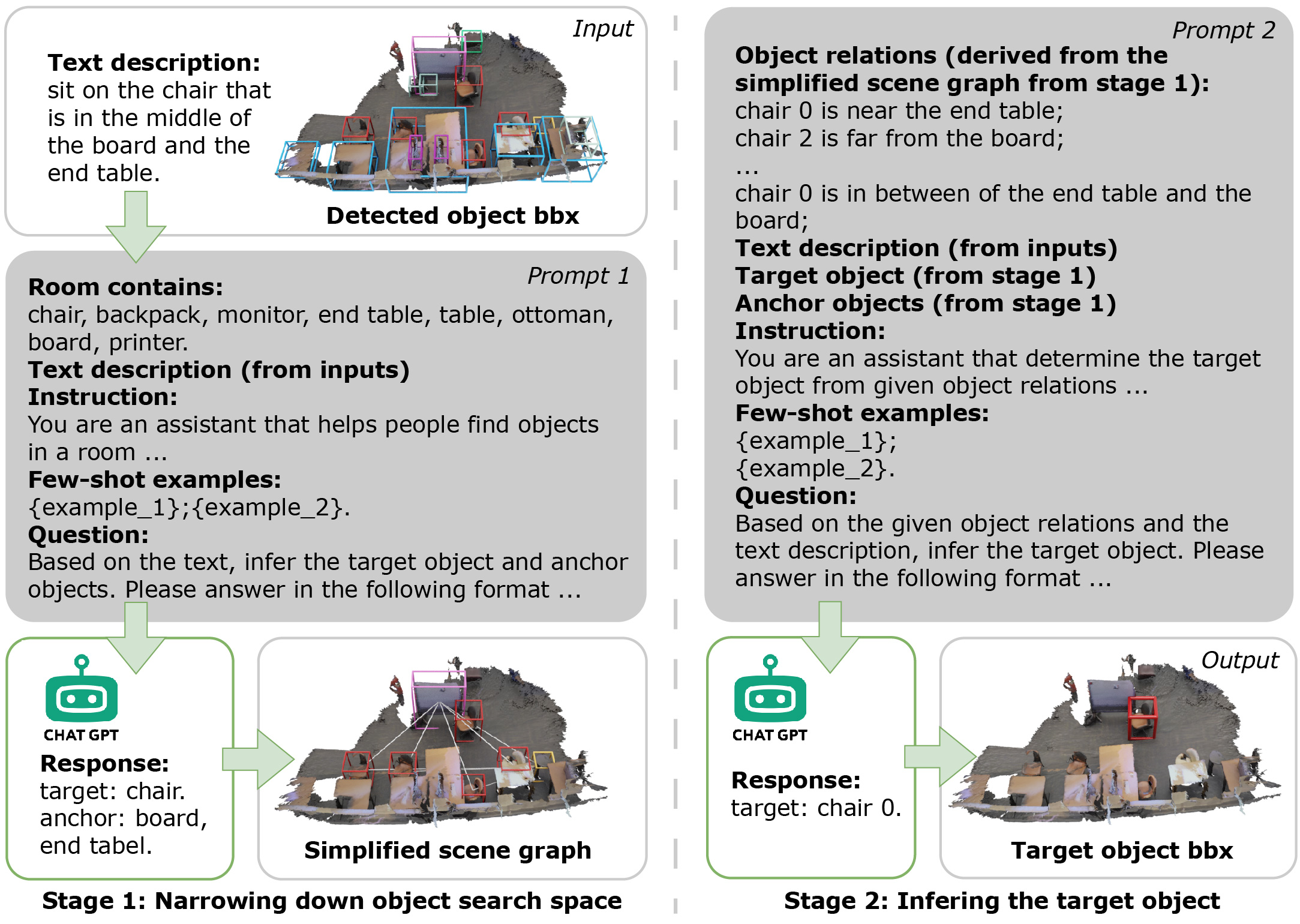
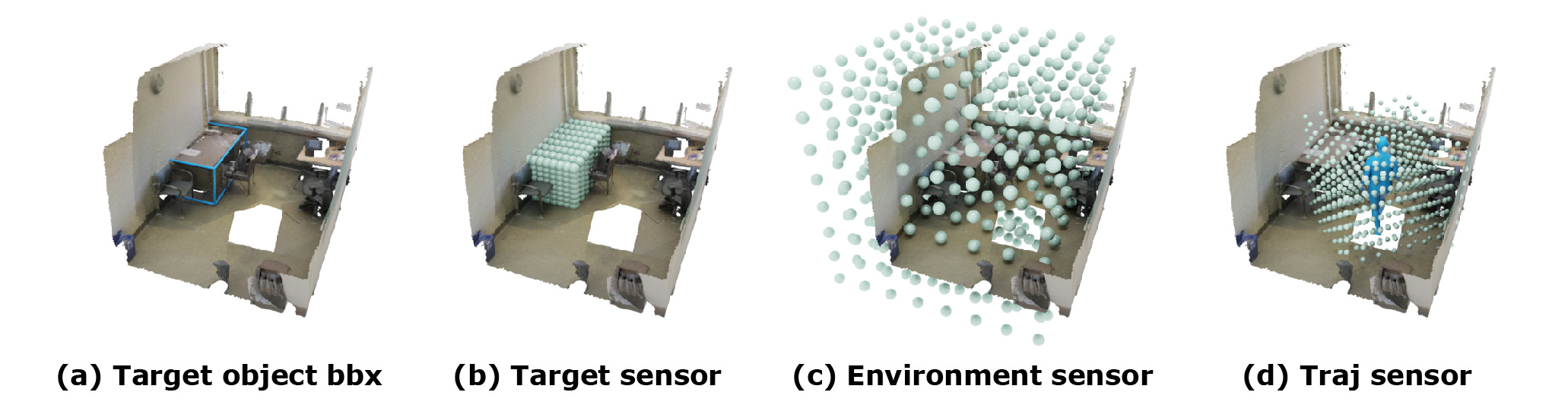
Method Overview
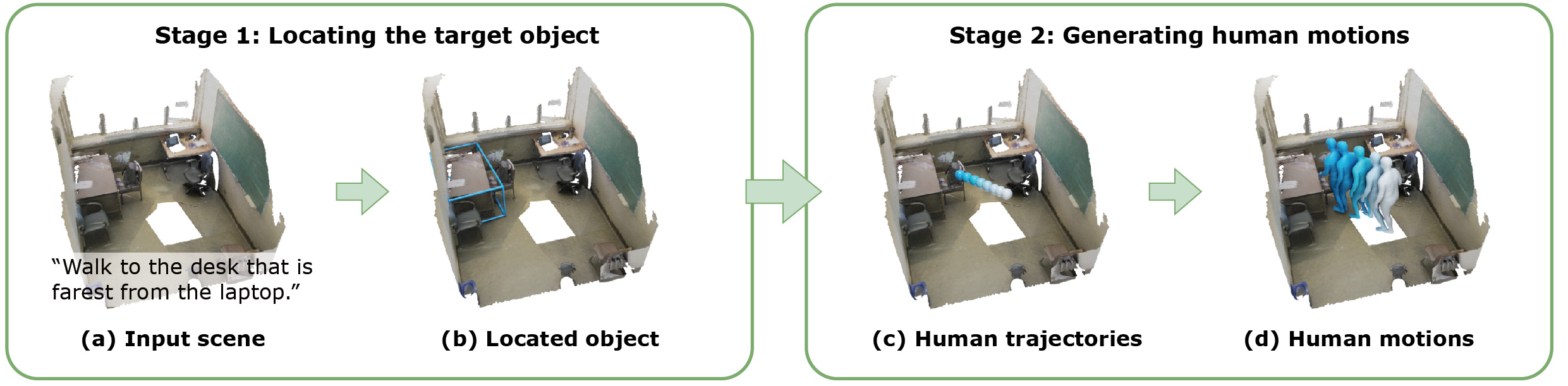
Overview of our two-stage pipeline. In the first stage, given an input scene and a text description (a), we use ChatGPT to locate the target object (b). In the second stage, human motions are synthesized by first producing human trajectories (c) and then generating local poses (d).