1. State Key Lab of CAD & CG, Zhejiang University 2. Graphics & AI Lab, University of Texas at Austin
* The first two authors contribute equally † Corresponding authors
A Video for introduction
Deal with occlusion
Visualizations of results on the Occlusion LINEMOD dataset. Green 3D bounding boxes represent the ground truth poses while blue 3D bounding boxes represent our predictions.







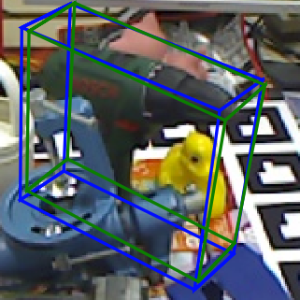





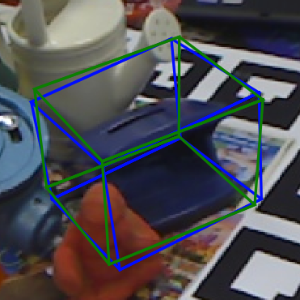


Deal with truncation
Visualizations of results on the Occlusion LINEMOD dataset. Green 3D bounding boxes represent the ground truth poses while blue 3D bounding boxes represent our predictions.















