Framework Overview
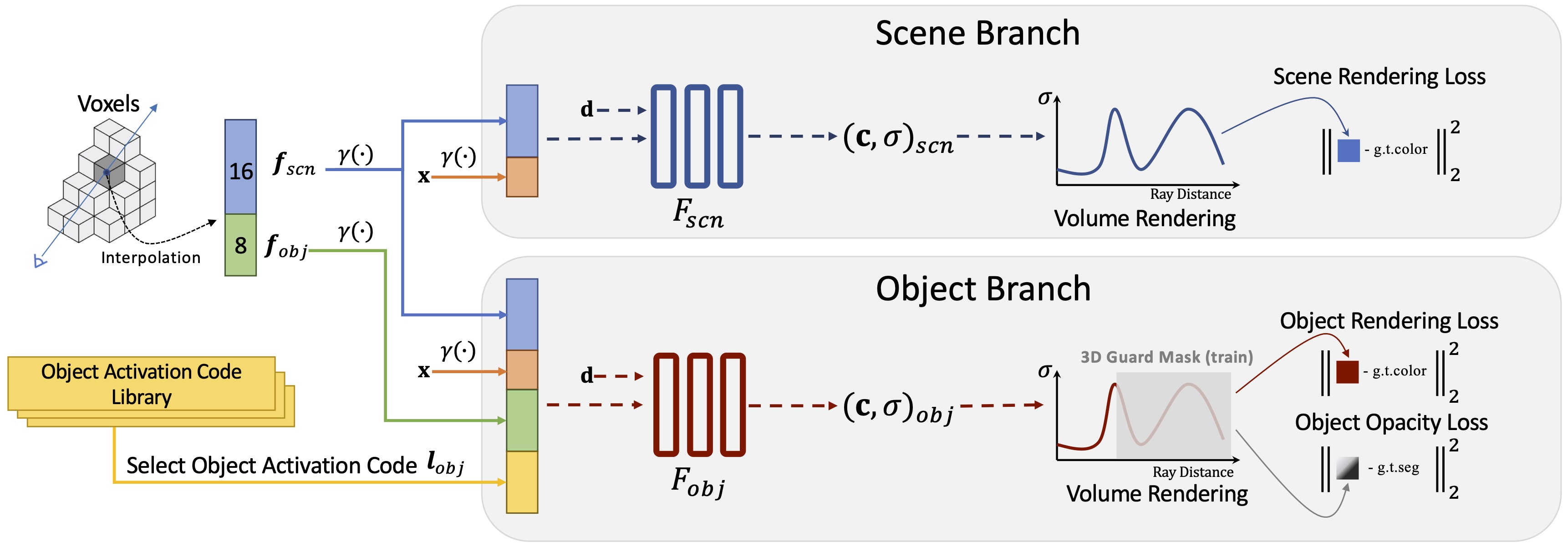
We design a two-pathway architecture for object-compositional neural radiance field. The scene branch takes the spatial coordinate $\mathbf{x}$, the interpolated scene voxel features $\boldsymbol{f}_{scn}$ at $\mathbf{x}$ and the ray direction $\mathbf{d}$ as input, and output the color $\mathbf{c}_{scn}$ and opacity $\sigma_{scn}$ of the scene. The object branch takes additional object voxel features $\boldsymbol{f}_{obj}$ as well a a object activation code $\boldsymbol{l}_{obj}$ to condition the output only contains the color $\mathbf{c}_{obj}$ and opacity $\sigma_{obj}$ for a specific object at its original location with everything else removed.