Pipeline overview
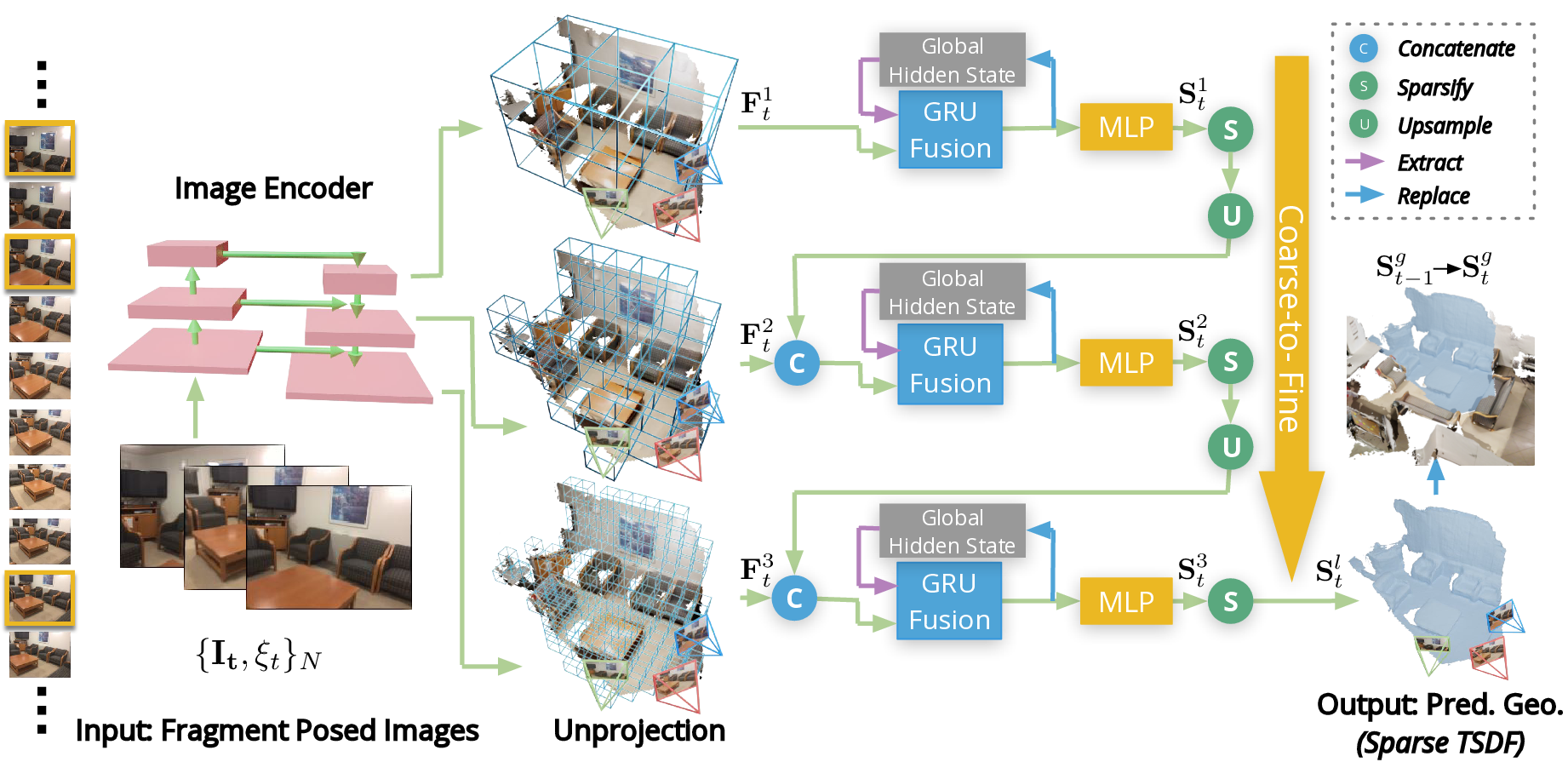
NeuralRecon predicts TSDF with a three-level coarse-to-fine approach that gradually increases the density of sparse voxels. Key-frame images in the local fragment are first passed through the image backbone to extract the multi-level features. These image features are later back-projected along each ray and aggregated into a 3D feature volume $\mathbf{F}_t^l$, where $l$ represents the level index. At the first level ($l=1$), a dense TSDF volume $\mathbf{S}_t^{1}$ is predicted. At the second and third levels, the upsampled $\mathbf{S}_t^{l-1}$ from the last level is concatenated with $\mathbf{F}_t^l$ and used as the input for the GRU Fusion and MLP modules. A feature volume defined in the world frame is maintained at each level as the global hidden state of the GRU. At the last level, the output $\mathbf{S}_t^l$ is used to replace corresponding voxels in the global TSDF volume $\mathbf{S}_t^{g}$, yielding the final reconstruction at time $t$.