Abstract
TL;DR: LoFTR can extract high-quality semi-dense matches even in indistinctive regions with low-textures, motion blur, or repetitive patterns.
We present a novel method for local image feature matching. Instead of performing image feature detection, description, and matching sequentially, we propose to first establish pixel-wise dense matches at a coarse level and later refine the good matches at a fine level. In contrast to dense methods that use cost volume to search correspondences, we use self and cross attention layers in Transformers to obtain feature descriptors that are conditioned on both images. The global receptive field provided by Transformers enables our method to produce dense matches in low-texture areas, where feature detectors usually struggle to produce repeatable interest points. The experiments on indoor and outdoor datasets show that LoFTR outperforms state-of-the-art methods by a large margin. LoFTR also ranks first on two public benchmarks of visual localization among the published methods.
Overview video (5 min)
Pipeline overview
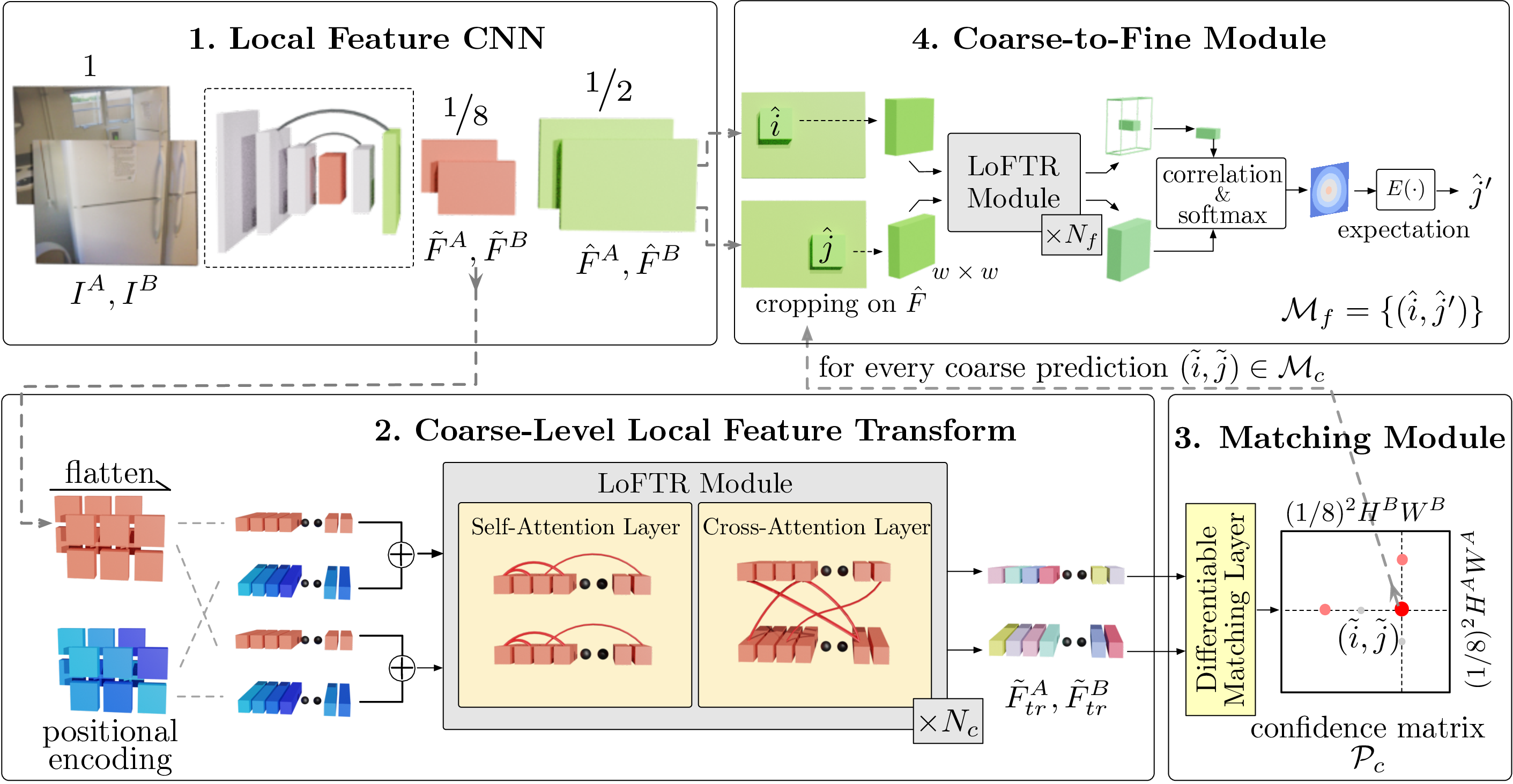
LoFTR has four components: \(\textbf{1.}\) A local feature CNN extracts the coarse-level feature maps $\tilde{F}^A$ and $\tilde{F}^B$, together with the fine-level feature maps $\hat{F}^A$ and $\hat{F}^B$ from the image pair $I^A$ and $I^B$. \(\textbf{2.}\) The coarse feature maps are flattened to 1-D vectors and added with the positional encoding. The added features are then processed by the Local Feature TRansformer (LoFTR) module, which has $N_c$ self-attention and cross-attention layers. \(\textbf{3.}\) A differentiable matching layer is used to match the transformed features, which ends up with a confidence matrix $\mathcal{P}_c$. The matches in $\mathcal{P}_c$ are selected according to the confidence threshold and mutual-nearest-neighbor criteria, yielding the coarse-level match prediction $\mathcal{M}_c$. \(\textbf{4.}\) For every selected coarse prediction $(\tilde{i}, \tilde{j}) \in \mathcal{M}_c$, a local window with size $w\times w$ is cropped from the fine-level feature map. Coarse matches will be refined within this local window to a sub-pixel level as the final match prediction $\mathcal{M}_f$.
Matches on a low-texture area
Data is captured using an iPhone, color indicates the match confidence.
Qualitative comparison with SuperGlue
Data is captured using an iPhone, color indicates the match confidence.
Visualizations on the attention weights and the transformed features in LoFTR

We use PCA to reduce the dimension of the transformed features and visualize the results with RGB color. The visualization for attention weights demonstrate that the features in indistinctive or low-texture regions are able to aggregate local and global context information through self-attention and cross-attention. In the first two examples, the query point from the low-texture region is able to aggregate the surrounding global information flexibly. For instance, the point on the chair is looking at the edge of the chair. In the last two examples, the query point from the distinctive region can also utilize the richer information from other regions. The feature visualization with PCA further shows that LoFTR learns a position-dependent feature representation.
Citation
@article{sun2021loftr,
title={{LoFTR}: Detector-Free Local Feature Matching with Transformers},
author={Sun, Jiaming and Shen, Zehong and Wang, Yuang and Bao, Hujun and Zhou, Xiaowei},
journal={CVPR},
year={2021}
}
Acknowledgements
We would like to specially thank Reviewer 1 for the insightful and constructive comments. We provide additional responses to Reviewer 1 regarding the naming of this paper in the supplementary material. We would like to thank Sida Peng and Qi Fang for the proof-reading, and Hongcheng Zhao for generating the visualizations.
Recommendations to other works from our group
Welcome to checkout our work on real-time 3D reconstruction (NeuralRecon) and human reconstruction (NeuralBody and Mirrored-Human) in CVPR 2021.