Abstract
The proposed network, excluding preprocessing (2D tracking, feature extraction, relative camera rotation estimation), takes 280 ms to process a 1430-frame (~45 seconds) video on an RTX 4090 GPU.
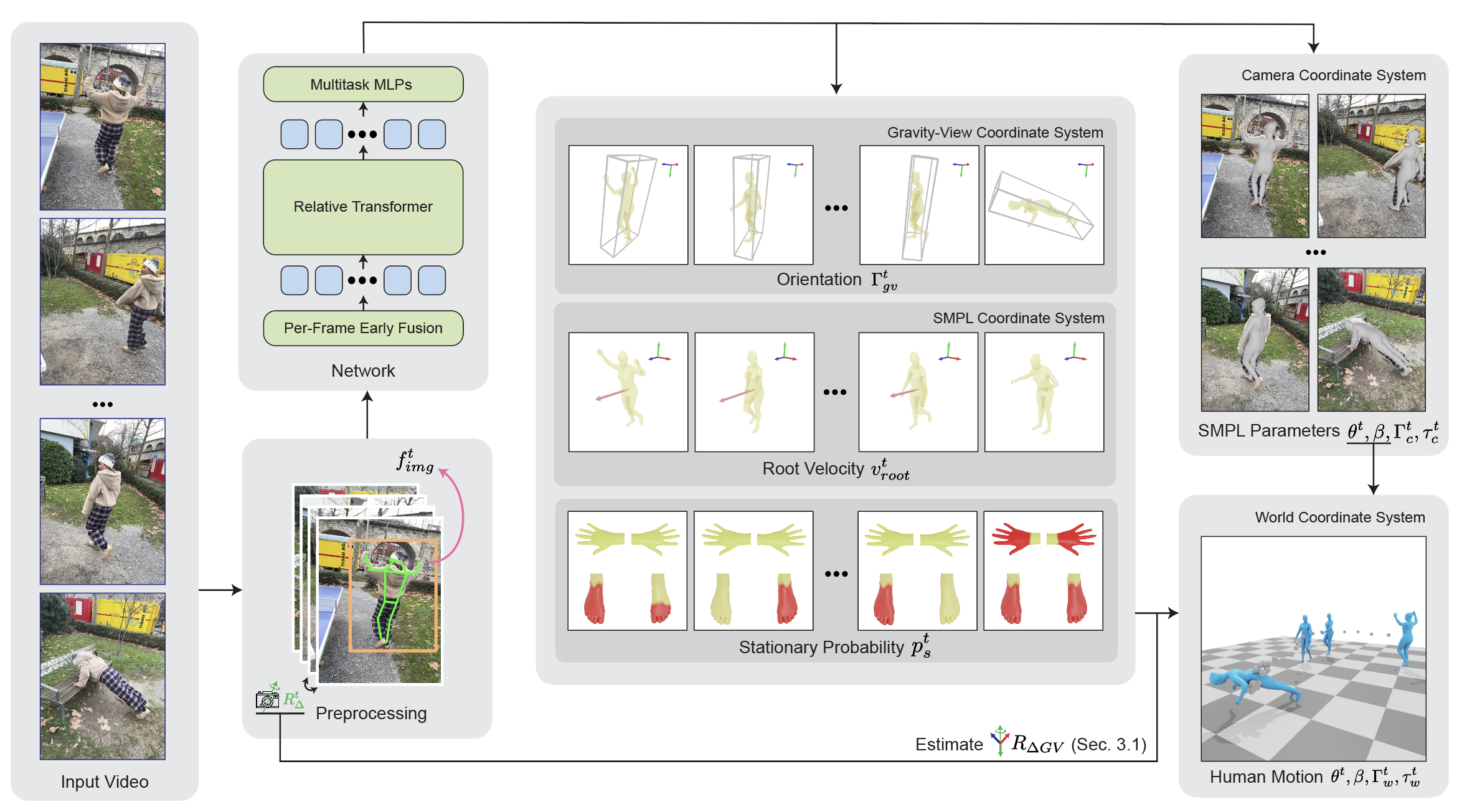
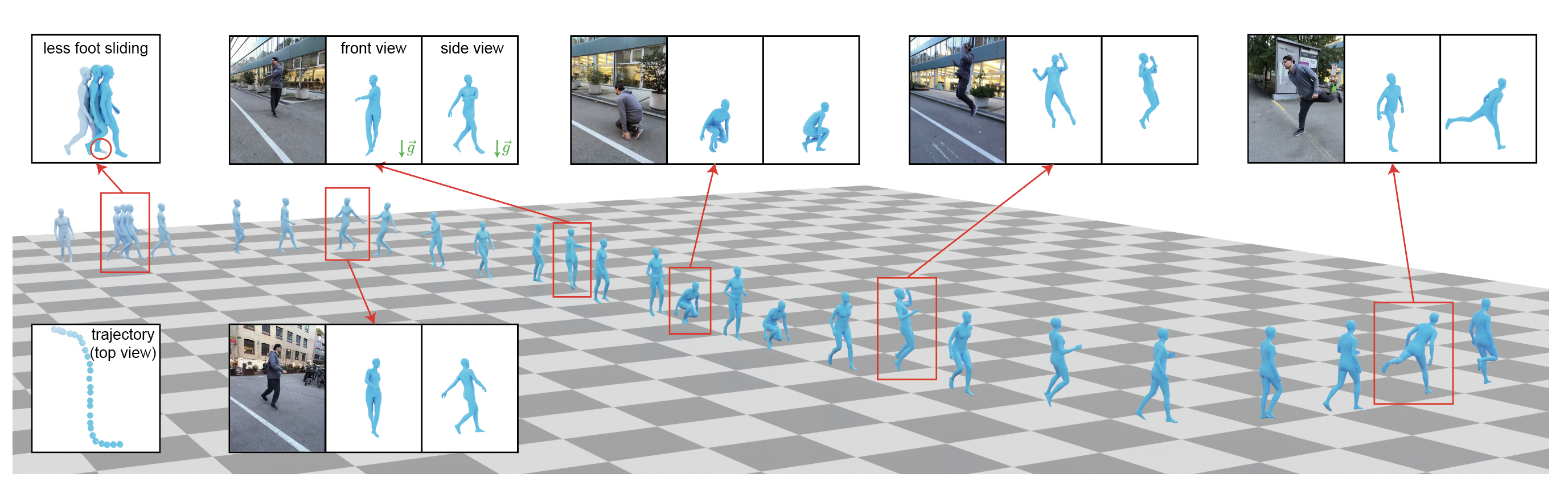
We present a novel method for recovering world-grounded human motion from monocular video.
The main challenge of this problem stems from the ambiguity of defining the world coordinate system that
varies from sequence to sequence. Previous approaches attempt to alleviate this issue by predicting relative
motion between frames in an autoregressive manner, but being prone to accumulative errors.
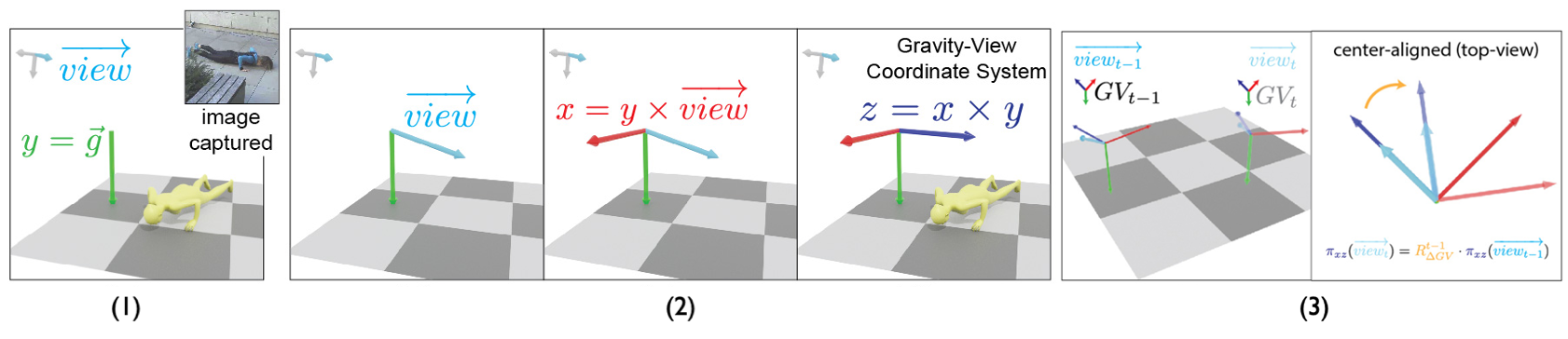
Instead, we propose to solve this challenge by estimating human poses in a novel Gravity-View (GV)
coordinate system, which is defined by the world gravity and the camera view direction.
The proposed GV system is naturally gravity-aligned and uniquely defined for each video frame, largely
decreasing the ambiguity of learning image-pose mapping.
The estimated poses in the GV frame can be transformed back to a world coordinate system given camera
motions to form a global motion sequence.
Also, the per-frame estimation avoids the error accumulation in the autoregressive methods.
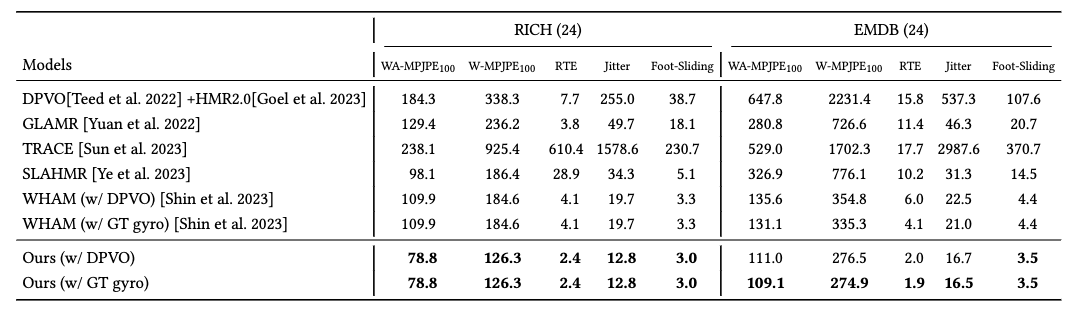
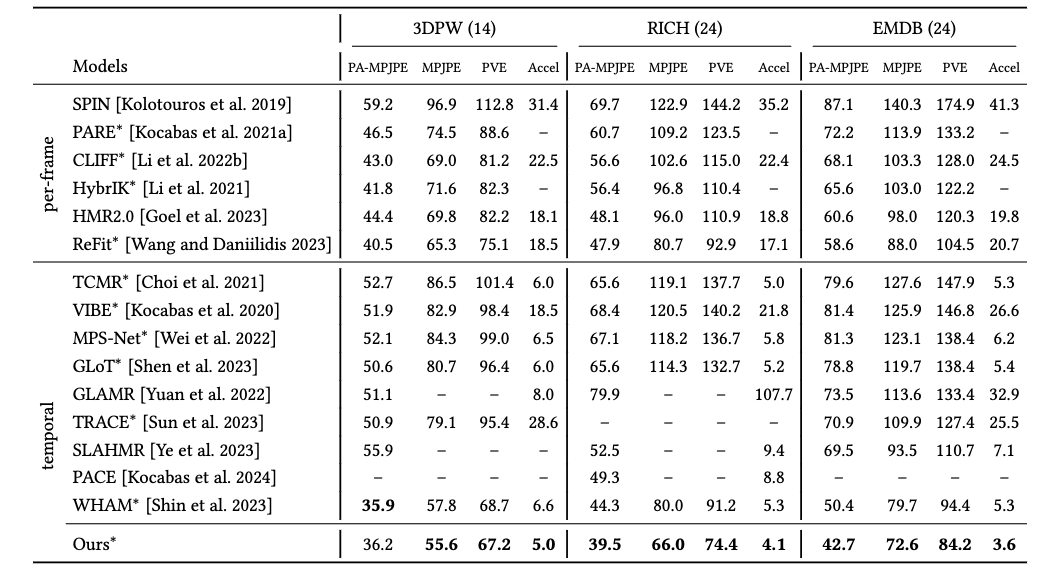
Experimental results on in-the-wild benchmarks demonstrate that our method can recover more realistic motion
in both the camera space and world-grounded settings, outperforming state-of-the-art methods in both
accuracy and speed.