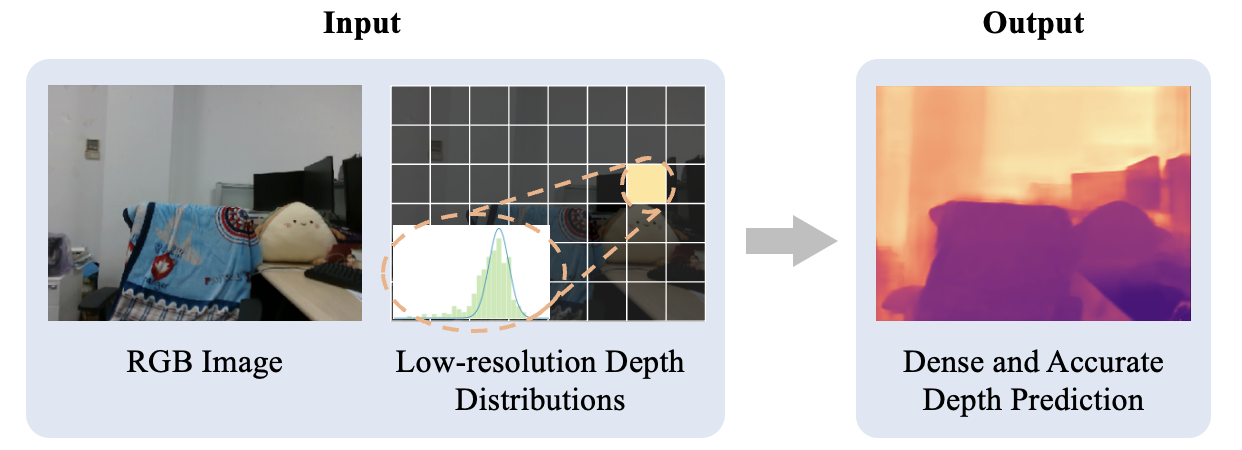
Abstract
Light-weight time-of-flight (ToF) depth sensors are small, cheap, low-energy and have been massively deployed on mobile devices for the purposes like autofocus, obstacle detection, etc. However, due to their specific measurements (depth distribution in a region instead of the depth value at a certain pixel) and extremely low resolution, they are insufficient for applications requiring high-fidelity depth such as 3D reconstruction. In this paper, we propose DELTAR, a novel method to empower light-weight ToF sensors with the capability of measuring high resolution and accurate depth by cooperating with a color image. As the core of DELTAR, a feature extractor customized for depth distribution and an attention-based neural architecture is proposed to fuse the information from the color and ToF domain efficiently. To evaluate our system in real-world scenarios, we design a data collection device and propose a new approach to calibrate the RGB camera and ToF sensor. Experiments show that our method produces more accurate depth than existing frameworks designed for depth completion and depth super-resolution and achieves on par performance with a commodity-level RGB-D sensor
Video
YouTube Source
What is the light-weight ToF sensor?
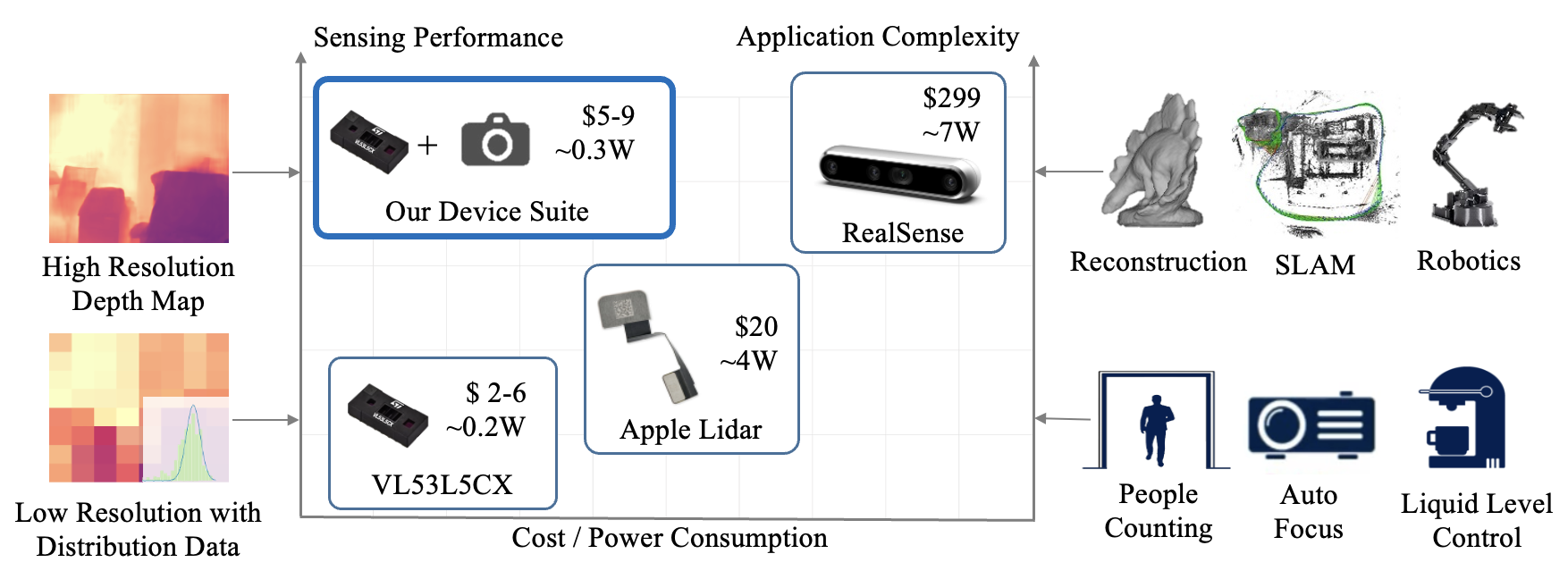
Light-weight ToF sensors like VL53L5CX are designed to be low-cost, small, and low-energy, which have been massively deployed on mobile devices for the purposes like autofocus, obstacle detection, etc. Due to the light-weight electronic design, the depth measured by these sensors has more uncertainty (i.e., in a distribution instead of single depth value) and low spatial resolution (e.g., ≤ 10×10), and thus cannot support applications like 3D reconstruction or SLAM, that require high-fidelity depth. In this paper, we show how to improve the depth quality to be on par with a commodity-level RGB-D sensor by our DELTAR algorithm.
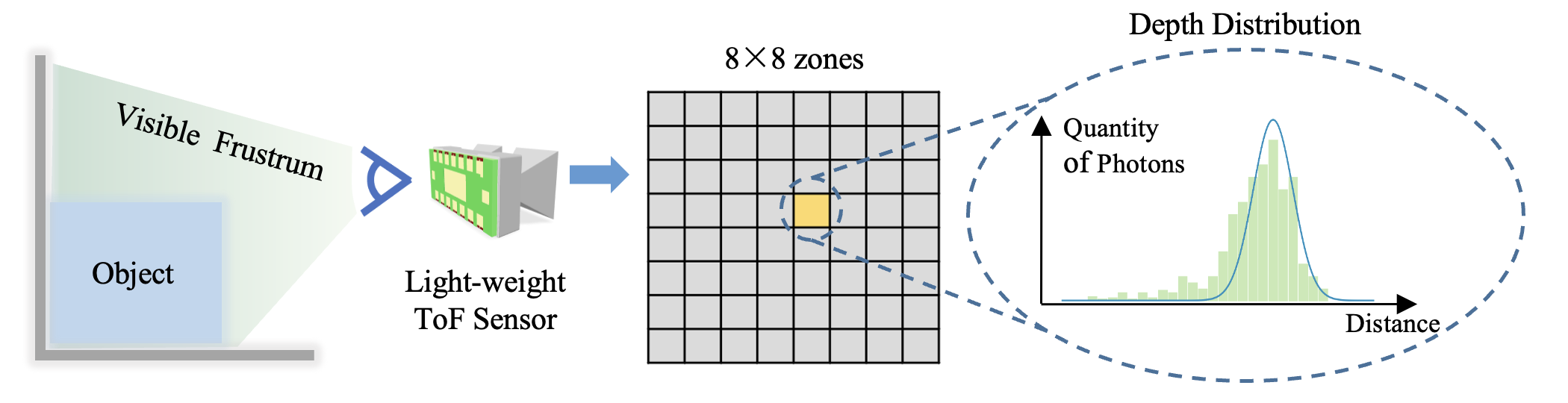
Let's use the VL53L5CX as an example to explain the sensing principle of the light-weight ToF sensor. For conventional ToF sensors, the output is typically in a resolution higher than 10 thousand pixels and measures the per-pixel distance along the ray from the optical center to the observed surfaces. In contrast, VL53L5CX (denoted as L5) provides multiple depth distributions with an extremely low resolution of 8 × 8 zones, covering 63° diagonal FoV in total. The distribution is originally measured by counting the number of photons returned in each discretized range of time, and then fitted with a Gaussian distribution in order to reduce the broadband load and energy consumption since only mean and variance needs to be transmitted.
Quantitative comparison with RealSense D435i
The input color image and L5 signals are shown in the left column. According to the status returned by L5, we hide the invalid zones which may receive too few photons or are unstable. Although the raw signals from L5 have extremely low resolution, we can improve its quality and make it even on par with RealSense Depth Sensor, by fully exploiting the capture depth distribution and fusing with color images.
Qualitative comparison on ZJU-L5 dataset

Since we are the first to utilize signals from the light-weight ToF sensor and color images to predict depth, there is no existing method for a direct comparison. Therefore, we pick three types of existing methods and let them make use of information from L5 as fully as possible. Monocular estimation method tends to make mistakes on some misleading textures. Guided depth super-resolution and completion produce overly blurry depths that are lack of geometry details. In contrast, our method learns to leverage the high resolution color image and low quality L5 reading, and produces the most accurate depths with sharp object boundaries.
BibTeX
@inproceedings{deltar,
title={DELTAR: Depth Estimation from a Light-weight ToF Sensor and RGB Image},
author={Li Yijin and Liu Xinyang and Dong Wenqi and Zhou han and Bao Hujun and Zhang Guofeng and Zhang Yinda and Cui Zhaopeng},
booktitle={European Conference on Computer Vision (ECCV)},
year={2022}
}