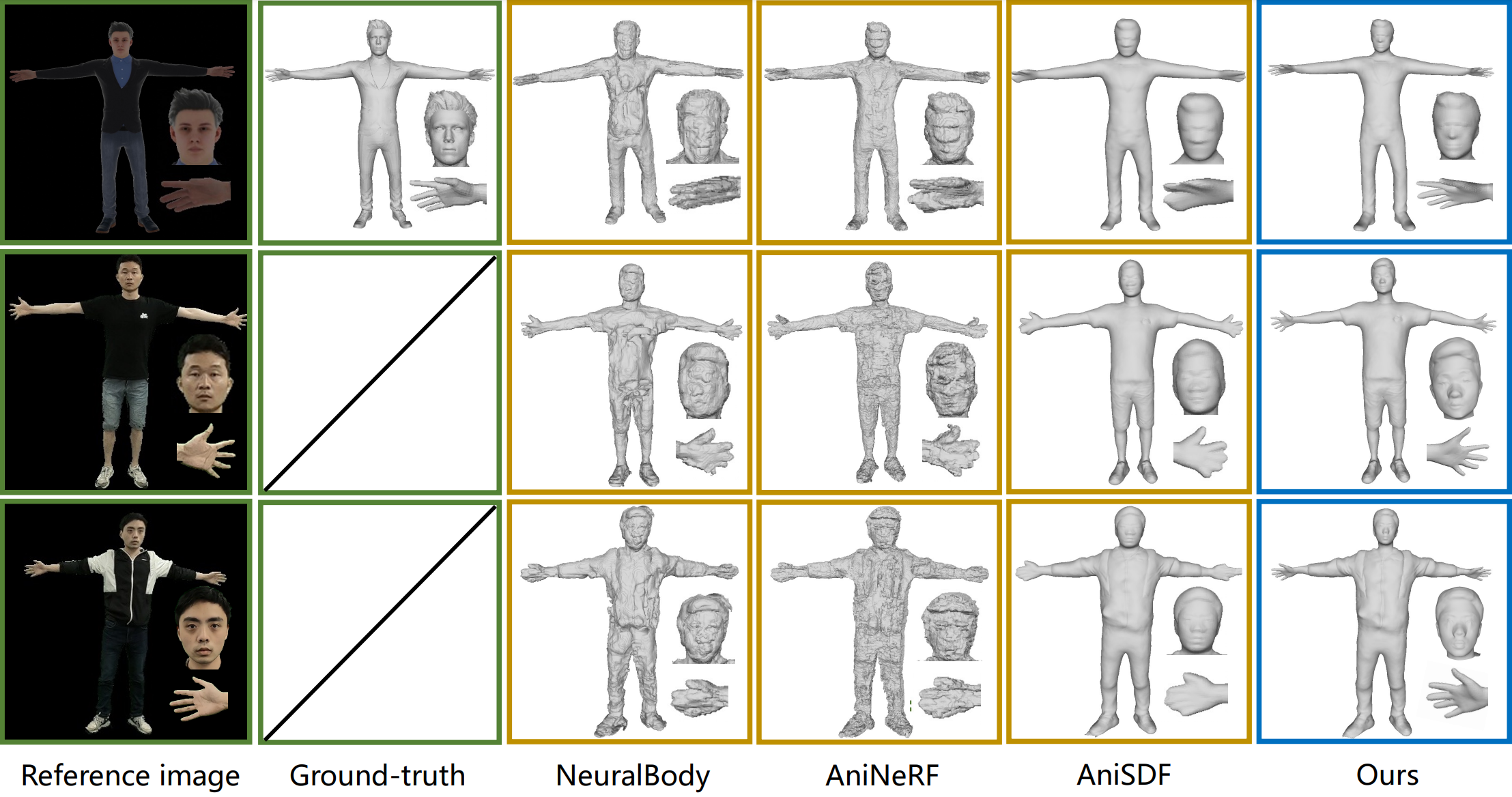
Geometry comparisons
1State Key Lab of CAD & CG, Zhejiang University
2Image Derivative Inc.
* denotes equal contribution
Recent advances in implicit neural representations make it possible to reconstruct a human-body model from a monocular self-rotation video. While previous works present impressive results of human body reconstruction, the quality of reconstructed face and hands are relatively low. The main reason is that the image region occupied by these parts is very small compared to the body. To solve this problem, we propose a new approach named TotalSelfScan, which reconstructs the full-body model from several monocular self-rotation videos that focus on the face, hands, and body, respectively. Compared to recording a single video, this setting has almost no additional cost but provides more details of essential parts. To learn the full-body model, instead of encoding the whole body in a single network, we propose a multi-part representation to model separate parts and then fuse the part-specific observations into a single unified human model. Once learned, the full-body model enables rendering photorealistic free-viewpoint videos under novel human poses. Experiments show that TotalSelfScan can significantly improve the reconstruction and rendering quality on the face and hands compared to the existing methods. The code is available at https://zju3dv.github.io/TotalSelfScan.
@inproceedings{dong2022totalselfscan,
title={TotalSelfScan: Learning Full-body Avatars from Self-Portrait Videos of Faces, Hands, and Bodies},
author={Dong, Junting and Fang, Qi and Guo, Yudong and Peng, Sida and Shuai, Qing and Zhou, Xiaowei and Bao, Hujun},
booktitle={Advances in Neural Information Processing Systems},
year={2022}
}